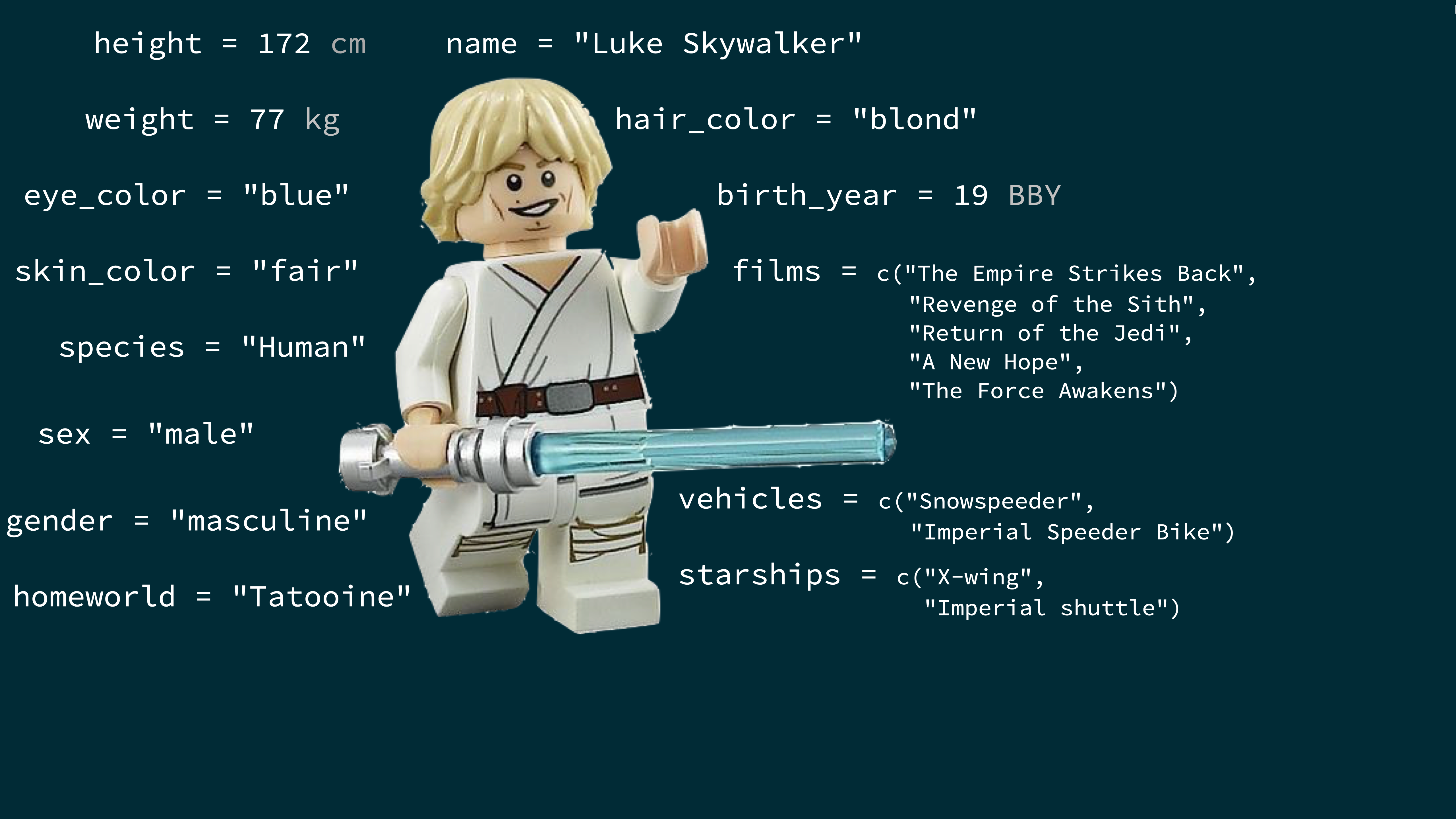
# A tibble: 87 × 14
name height mass hair_color skin_color eye_color birth_year sex gender
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Luke Sk… 172 77 blond fair blue 19 male mascu…
2 C-3PO 167 75 <NA> gold yellow 112 none mascu…
3 R2-D2 96 32 <NA> white, bl… red 33 none mascu…
4 Darth V… 202 136 none white yellow 41.9 male mascu…
5 Leia Or… 150 49 brown light brown 19 fema… femin…
6 Owen La… 178 120 brown, gr… light blue 52 male mascu…
7 Beru Wh… 165 75 brown light blue 47 fema… femin…
8 R5-D4 97 32 <NA> white, red red NA none mascu…
9 Biggs D… 183 84 black light brown 24 male mascu…
10 Obi-Wan… 182 77 auburn, w… fair blue-gray 57 male mascu…
# … with 77 more rows, and 5 more variables: homeworld <chr>, species <chr>,
# films <list>, vehicles <list>, starships <list>Biological Stats 2: Lecture 3
01/24/2023
Luke Skywalker
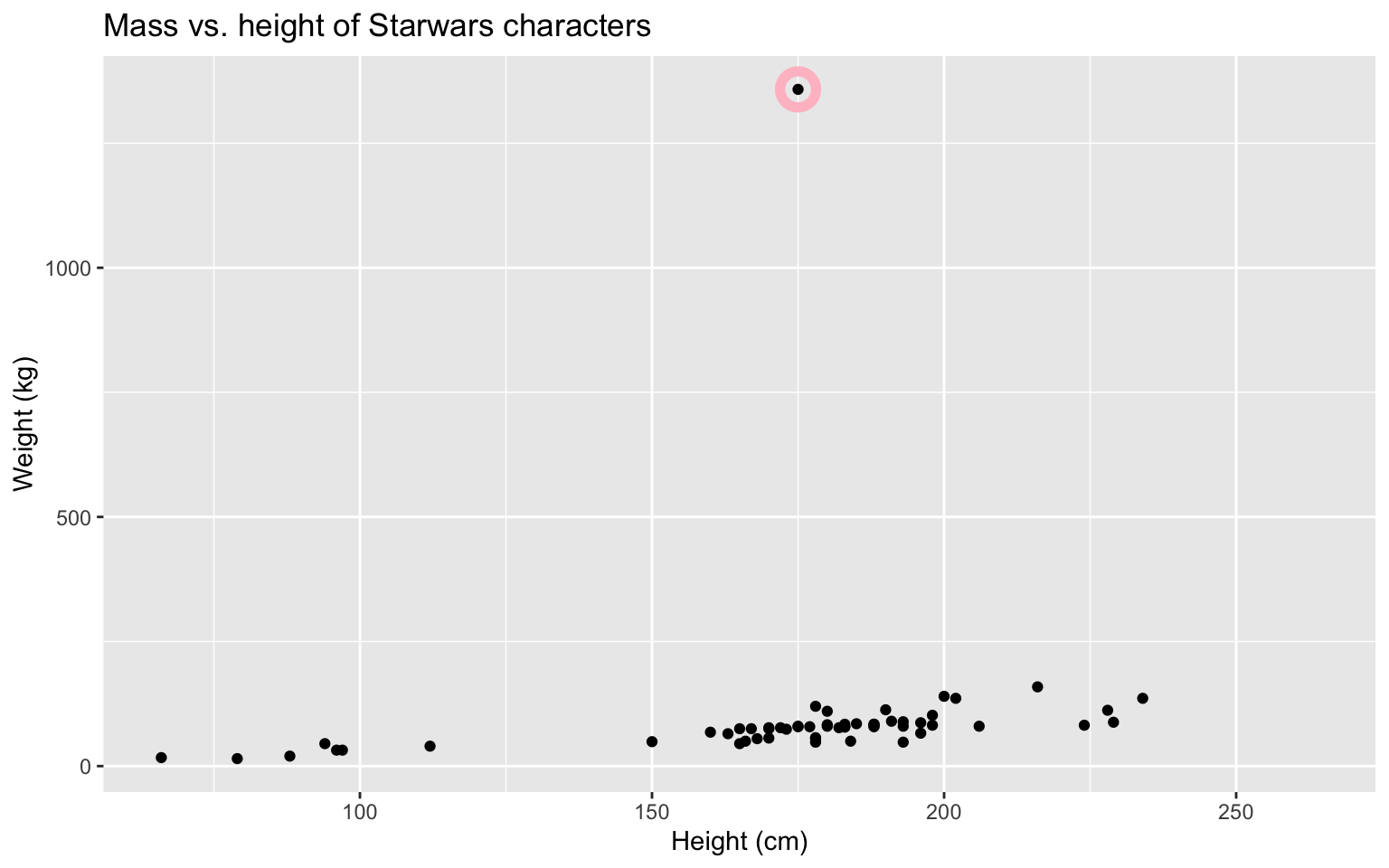
Mass vs. height
How would you describe the relationship between mass and height of Starwars characters? What other variables would help us understand data points that don’t follow the overall trend? Who is the not so tall but chonky character?
Jabba!
quartz_off_screen
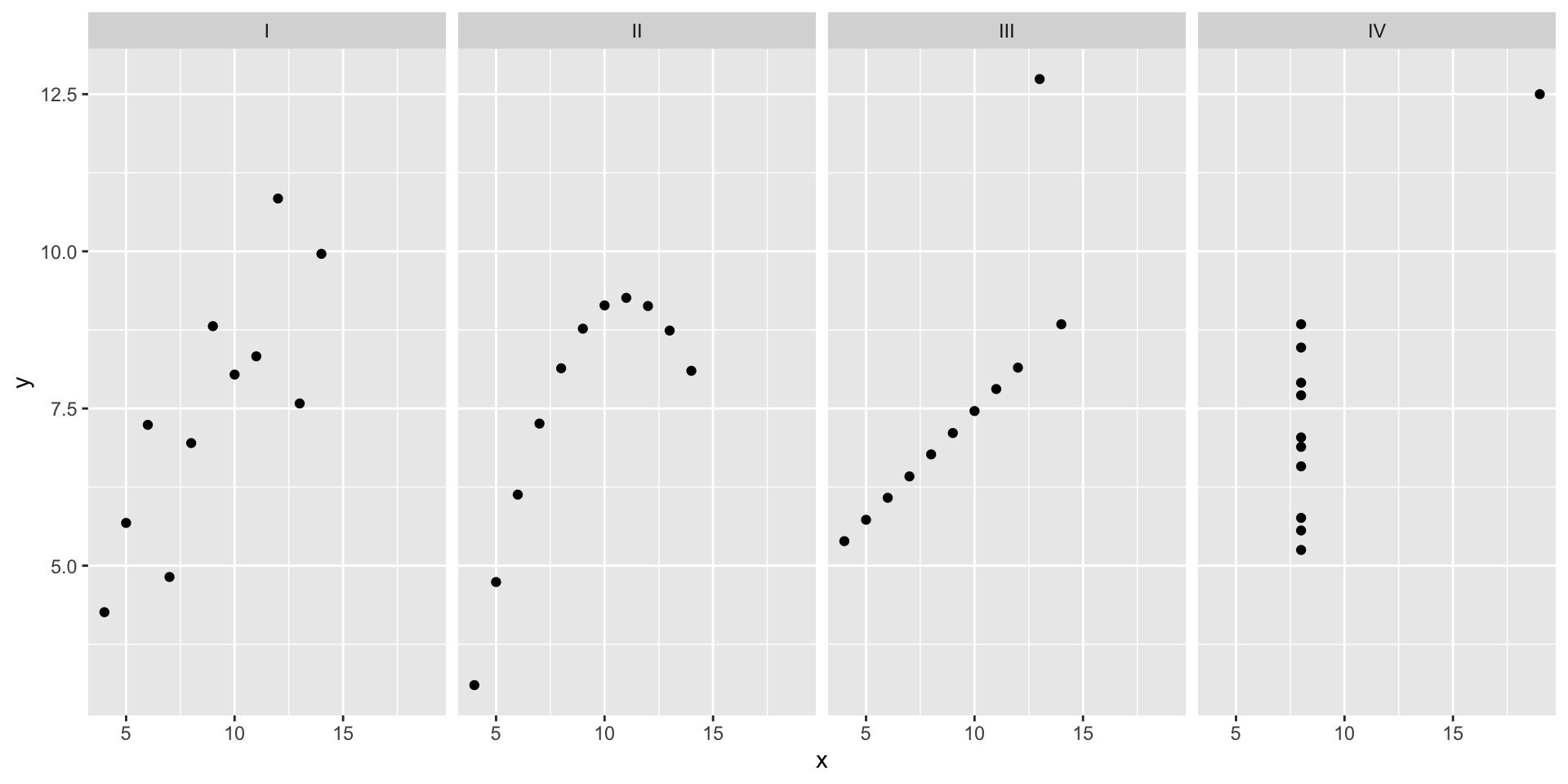
2 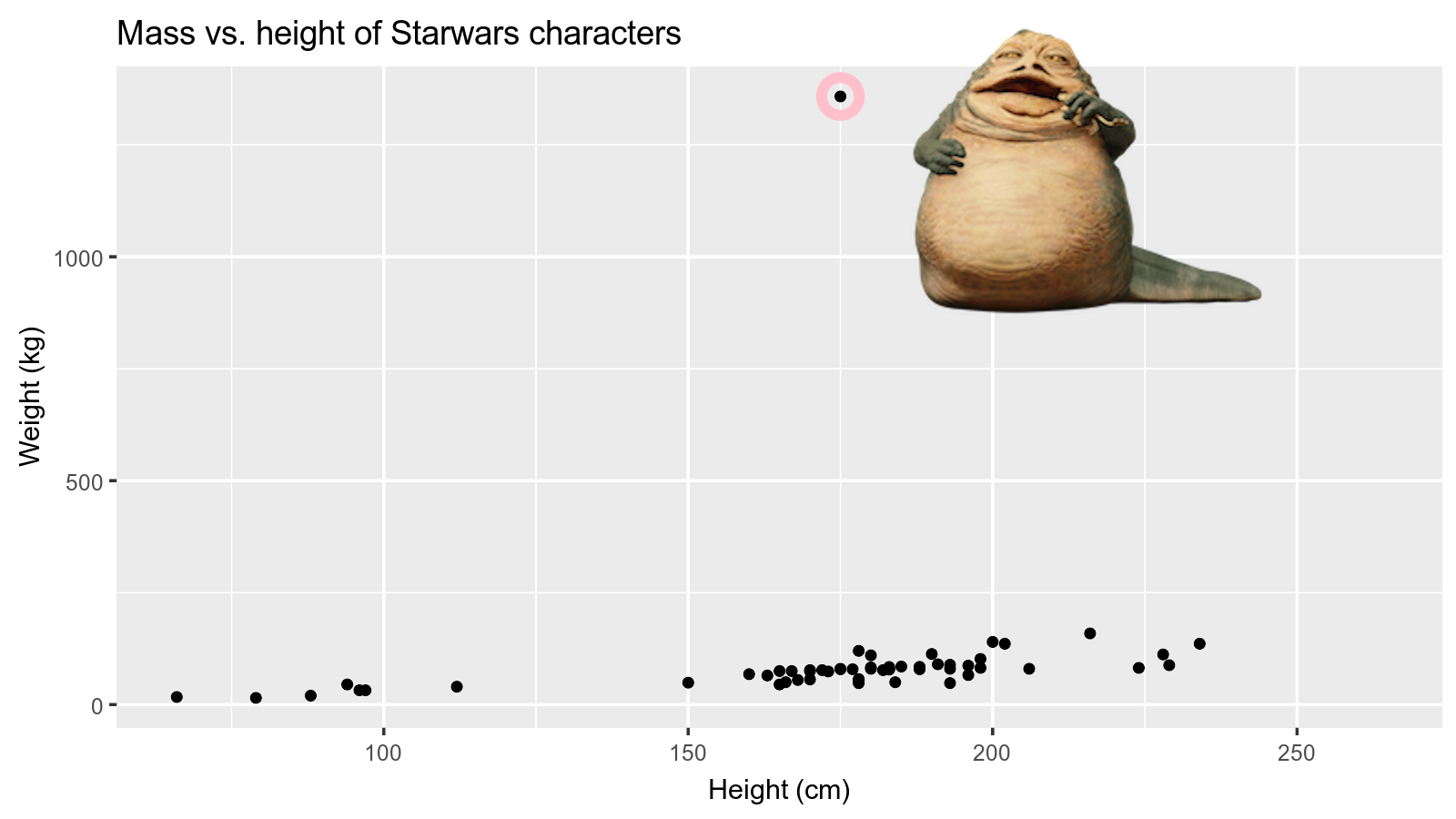
Visualizing Anscombe’s quartet
Data: Palmer Penguins
Measurements for penguin species, on islands in Palmer Archipelago, size (flipper length, body mass, bill dimensions), and sex. Horst et al. 2022. R Journal

Rows: 344
Columns: 8
$ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adel…
$ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torgerse…
$ bill_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.1, …
$ bill_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.1, …
$ flipper_length_mm <int> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, 186…
$ body_mass_g <int> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 3475, …
$ sex <fct> male, female, female, NA, female, male, female, male…
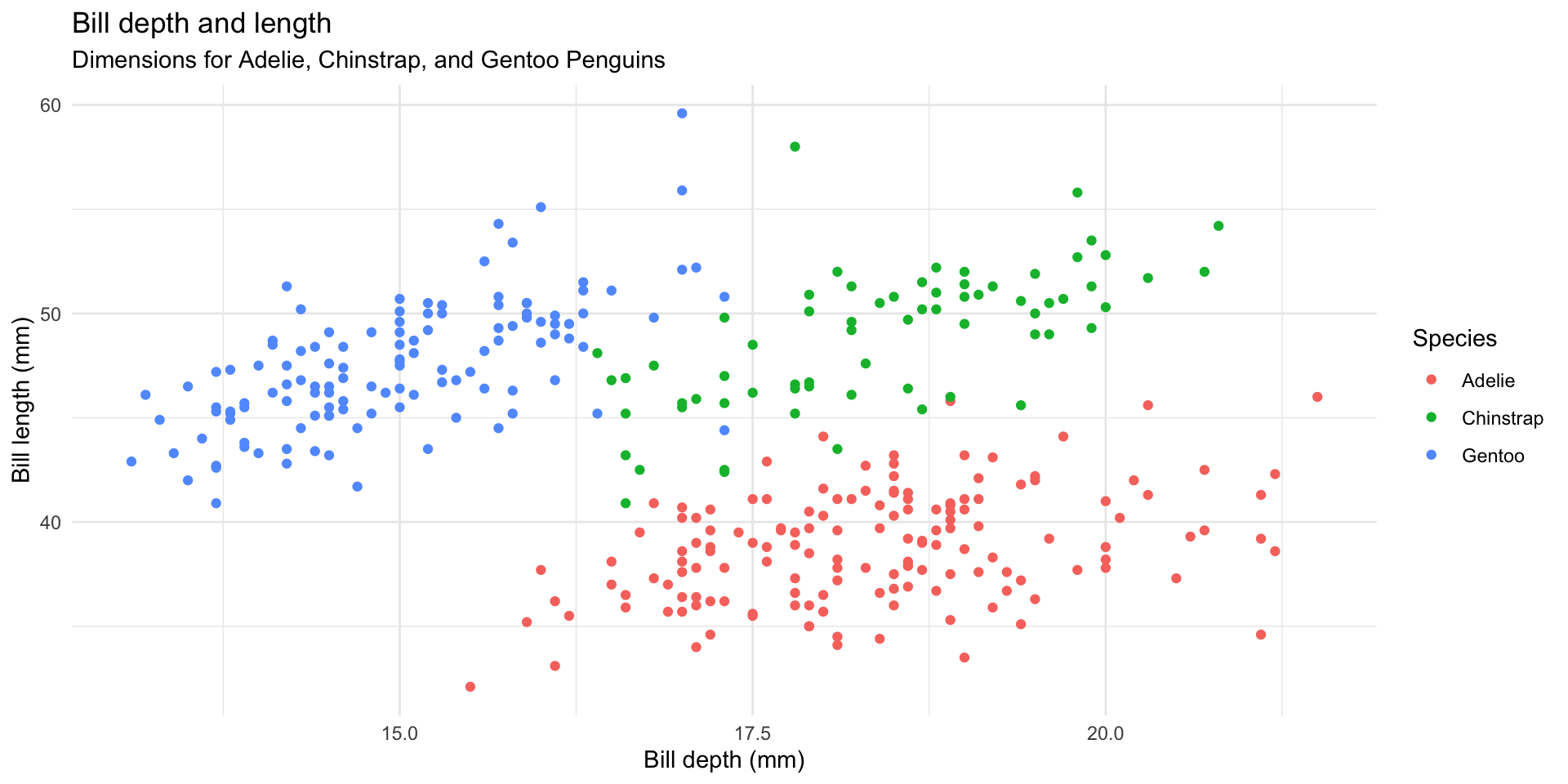
$ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…Palmer Penguins
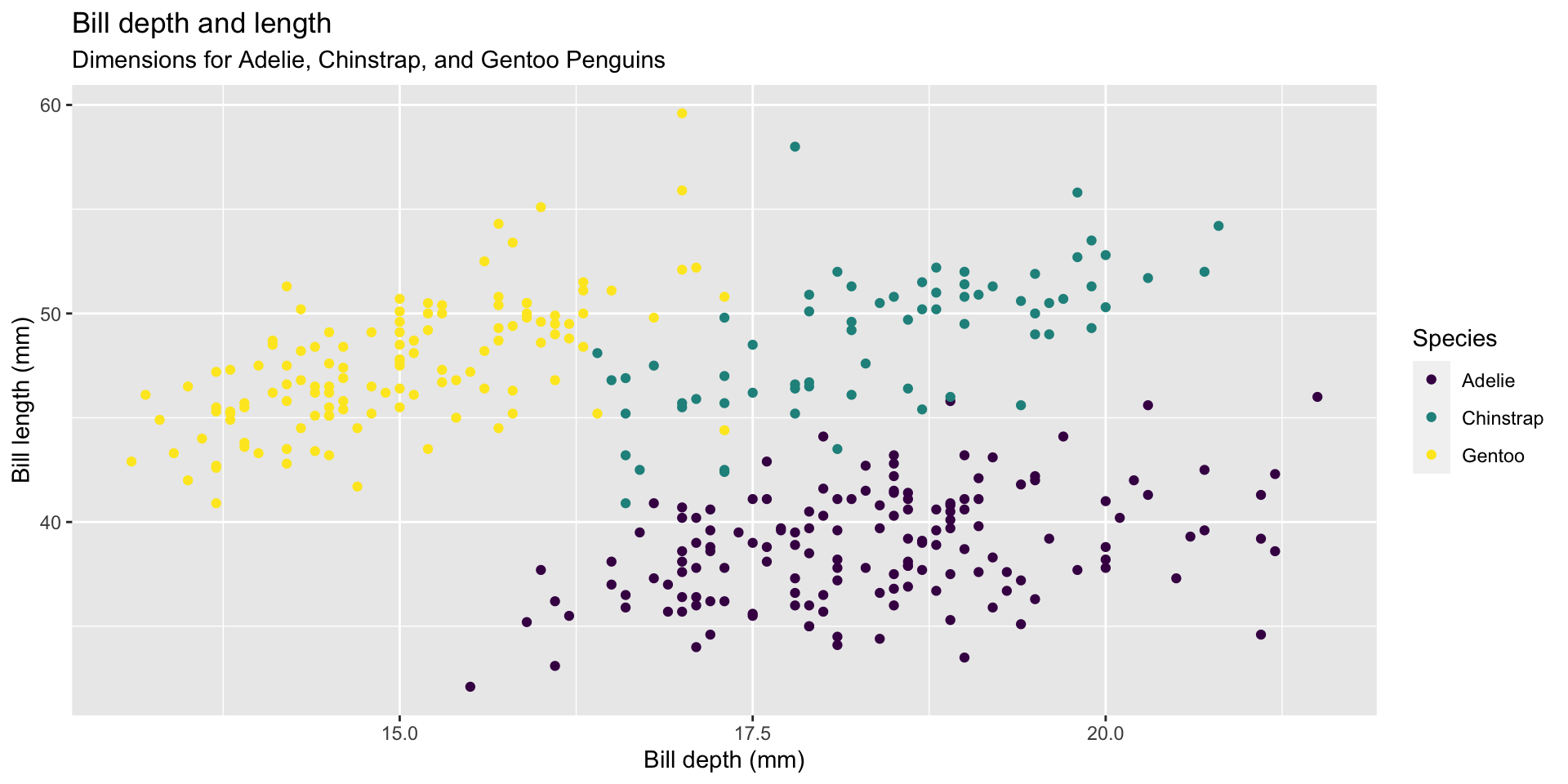
ggplot(data = penguins,
mapping = aes(x = bill_depth_mm, y = bill_length_mm,
colour = species)) +
geom_point() +
labs(title = "Bill depth and length",
subtitle = "Dimensions for Adelie, Chinstrap, and Gentoo Penguins",
x = "Bill depth (mm)", y = "Bill length (mm)",
colour = "Species") +
scale_color_viridis_d()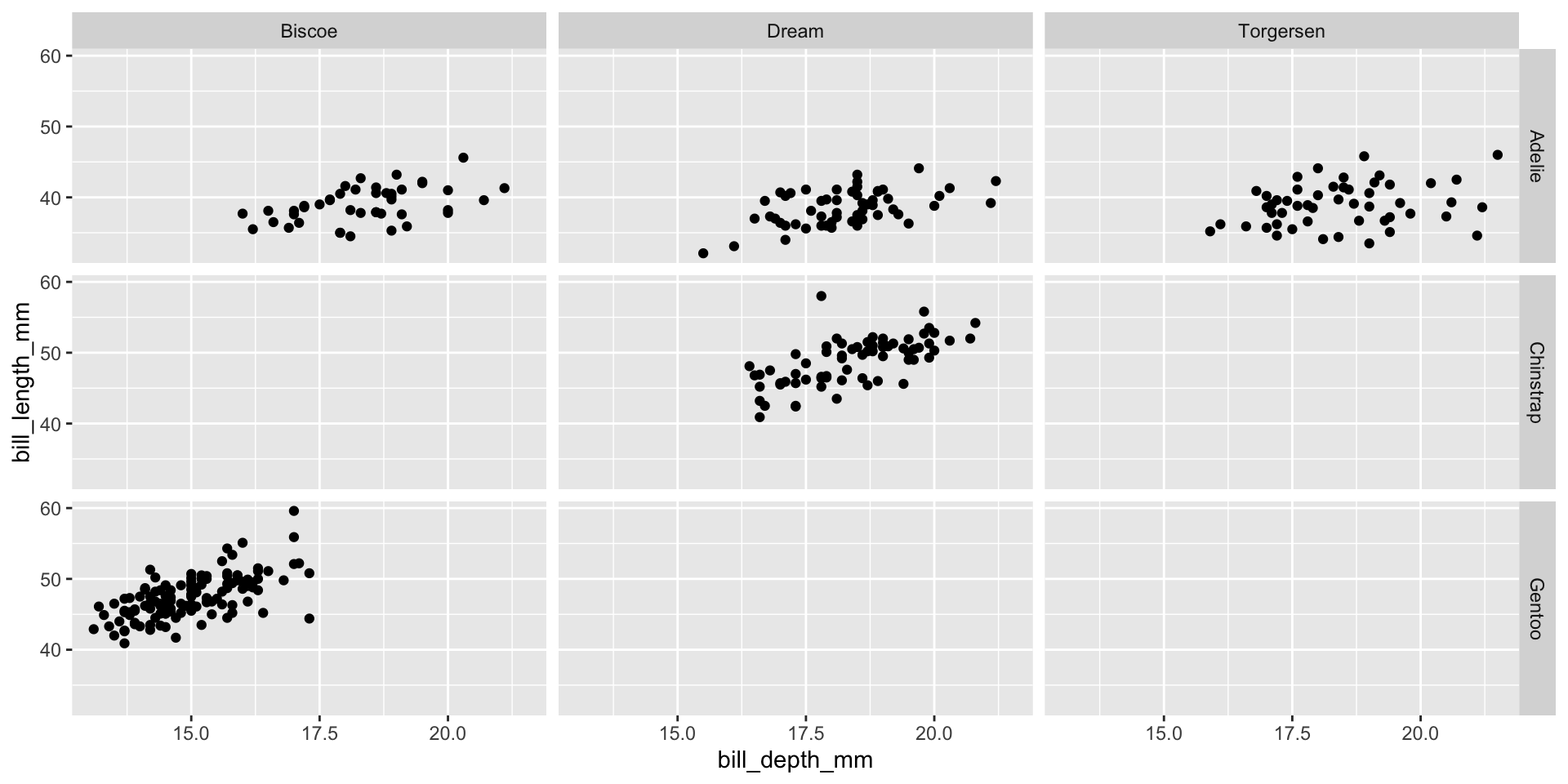
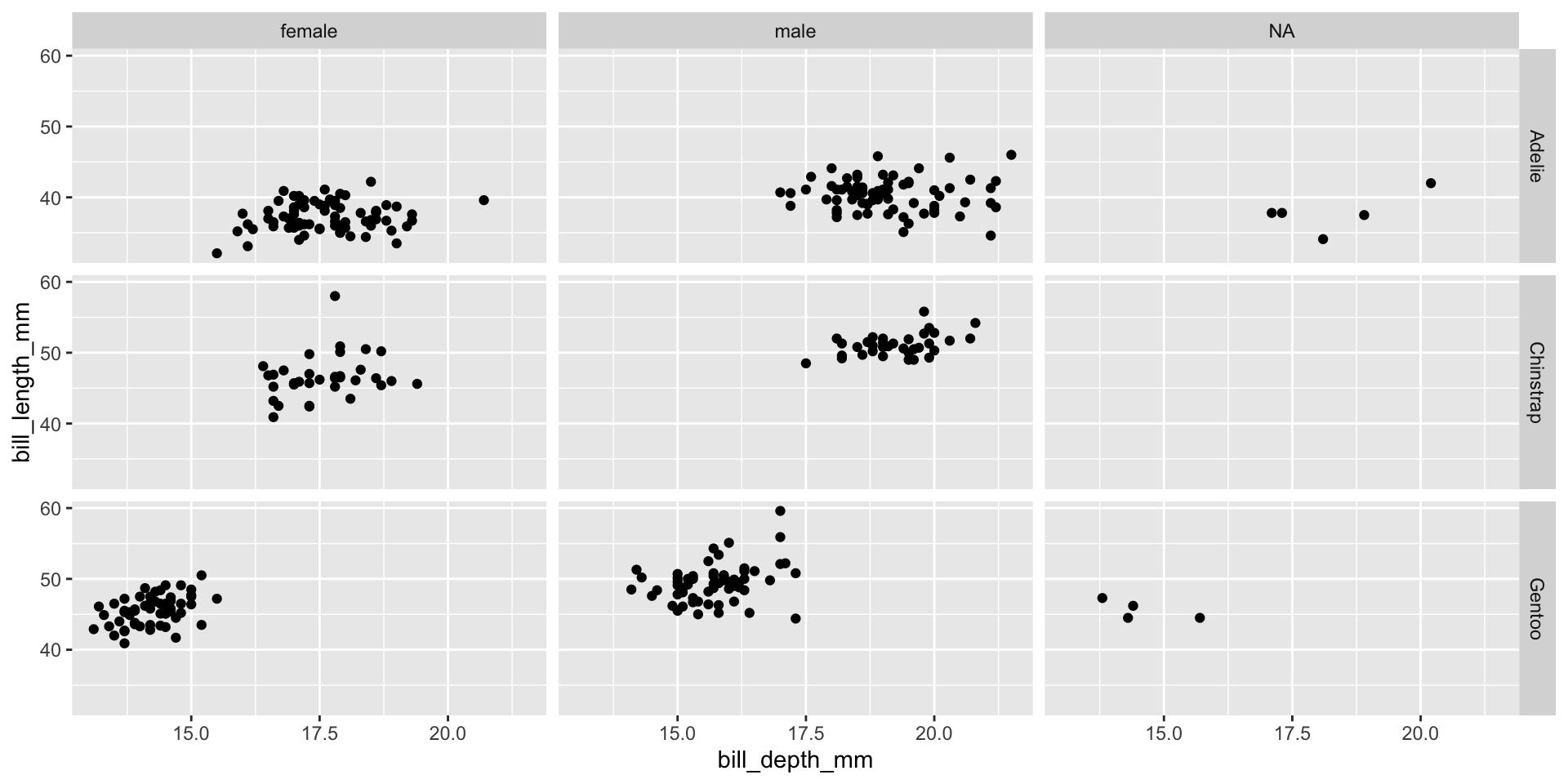
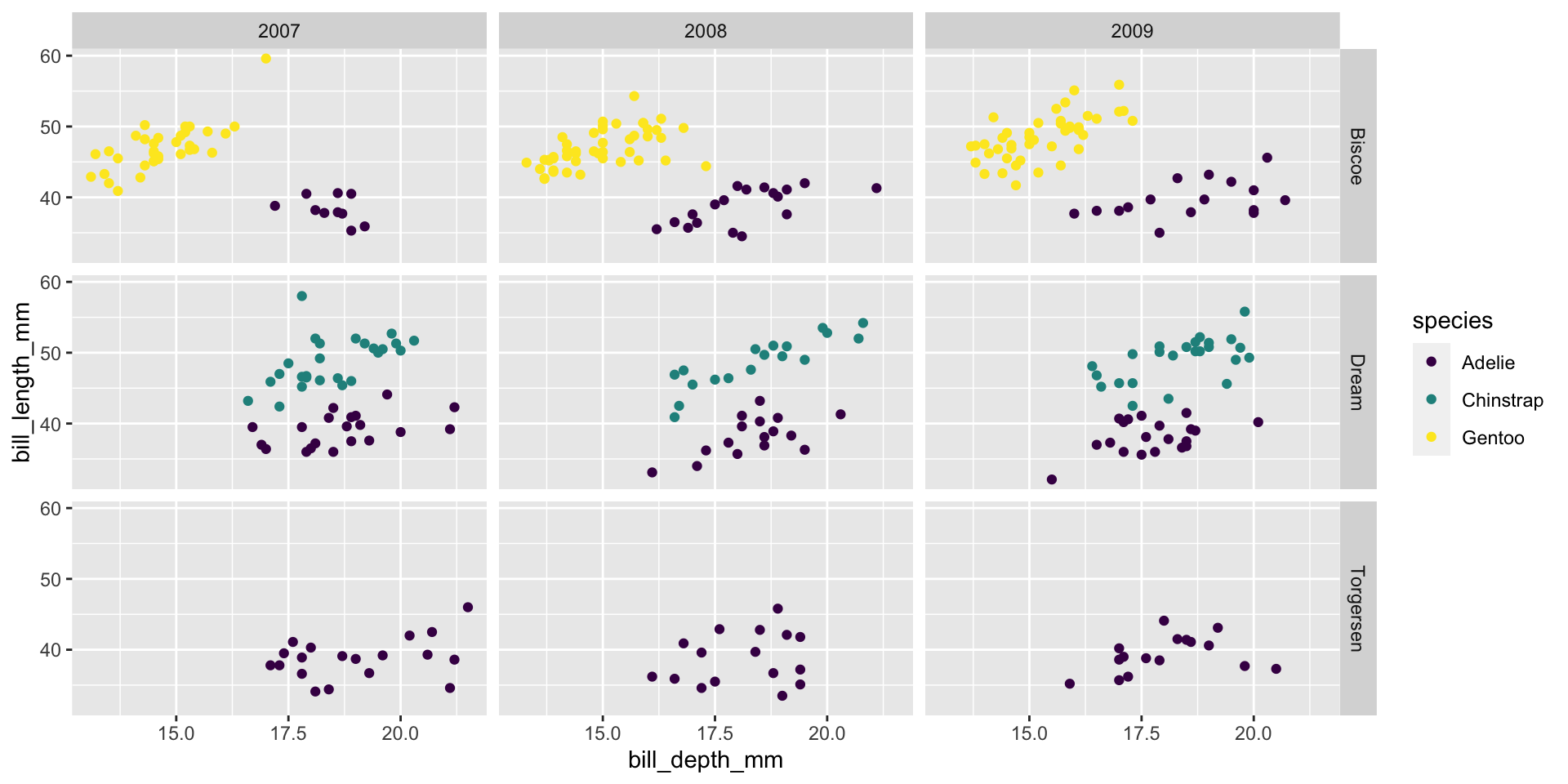
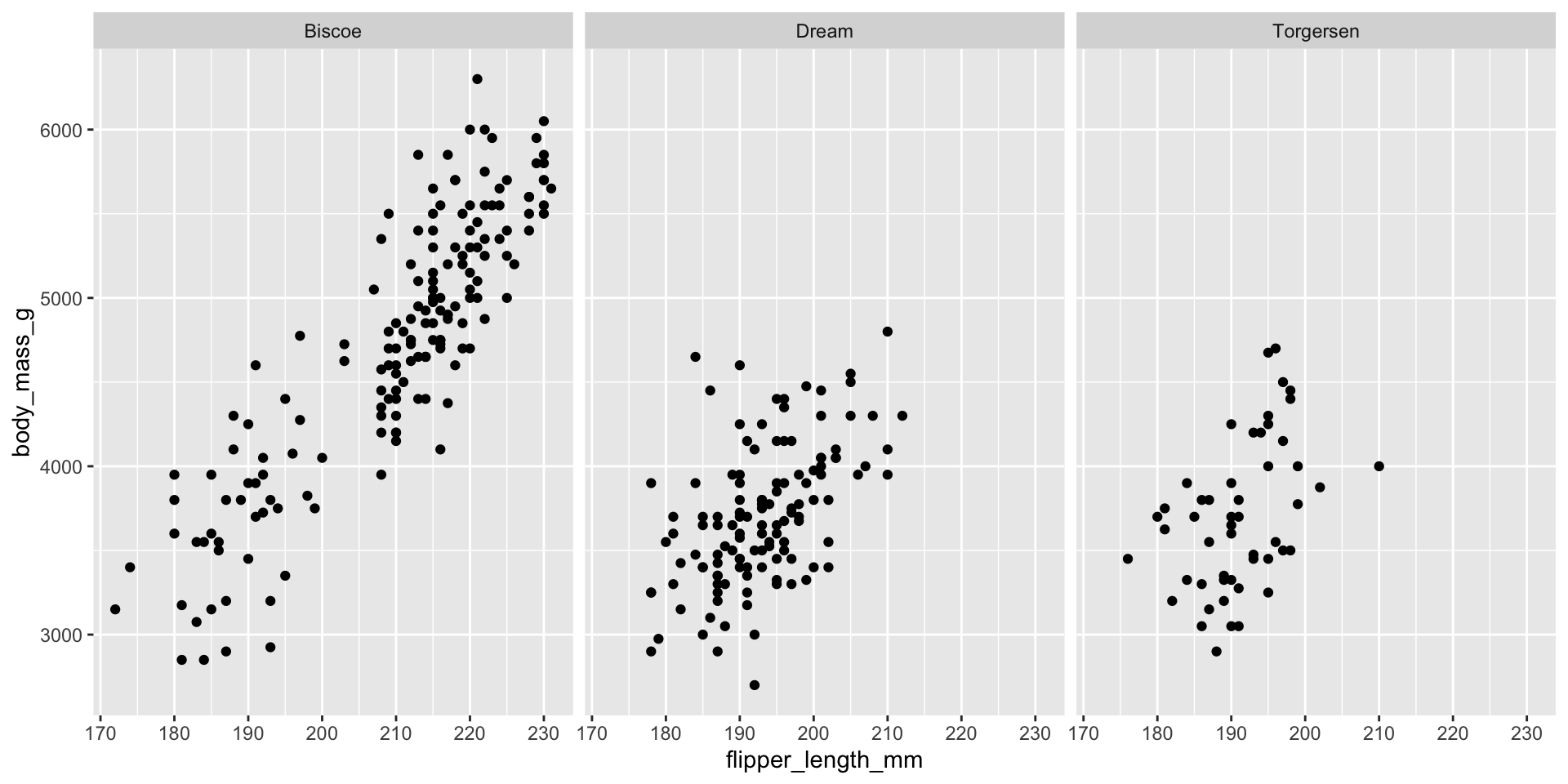
Facet and color
Data: Lending Club
Thousands of loans made through the Lending Club, which is a platform that allows individuals to lend to other individuals
Not all loans are created equal – ease of getting a loan depends on (apparent) ability to pay back the loan
Data includes loans made, these are not loan applications

Histogram
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.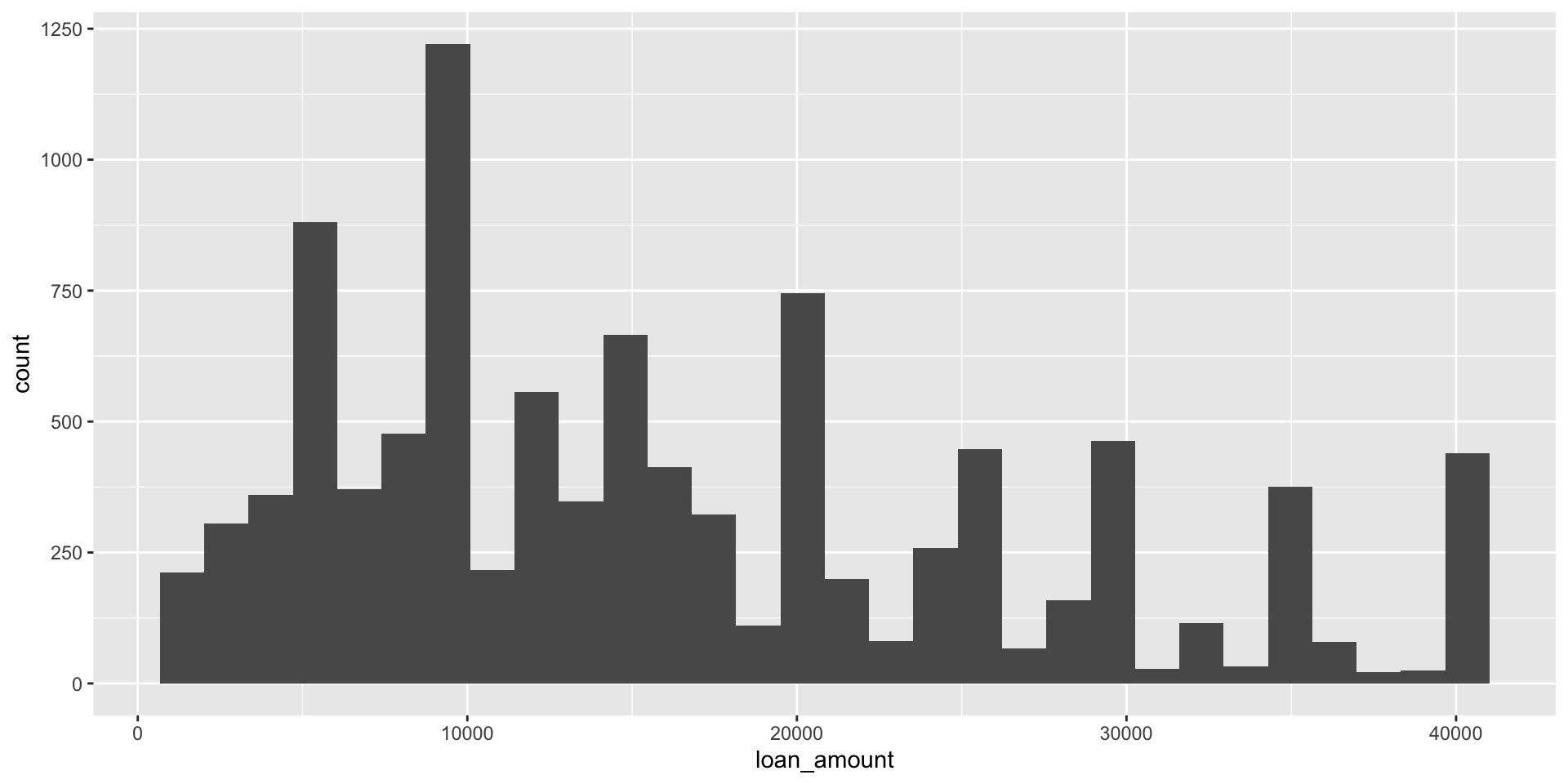
Histograms and binwidth
binwidth = 1000
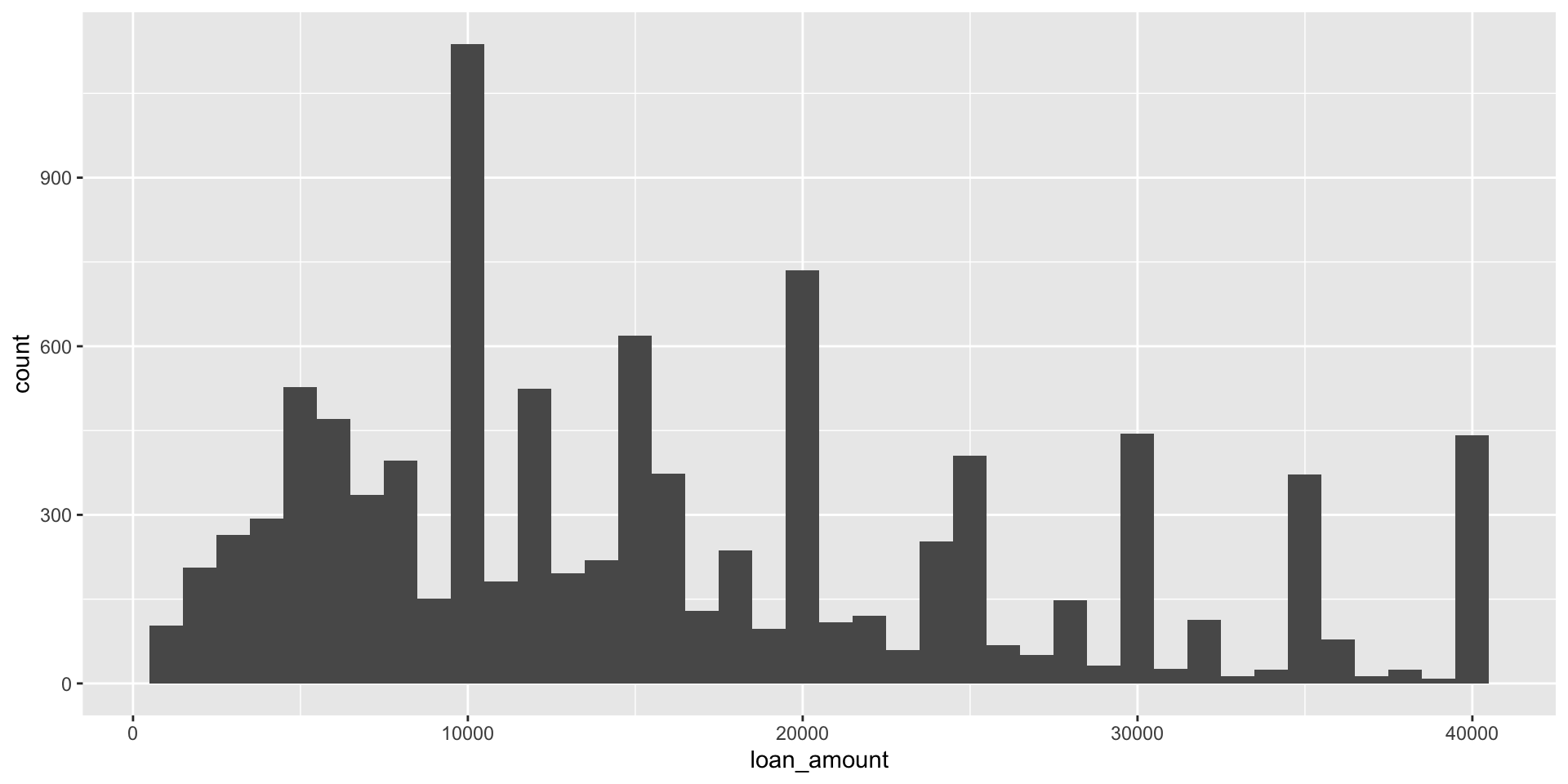
Histograms and binwidth
binwidth = 5000
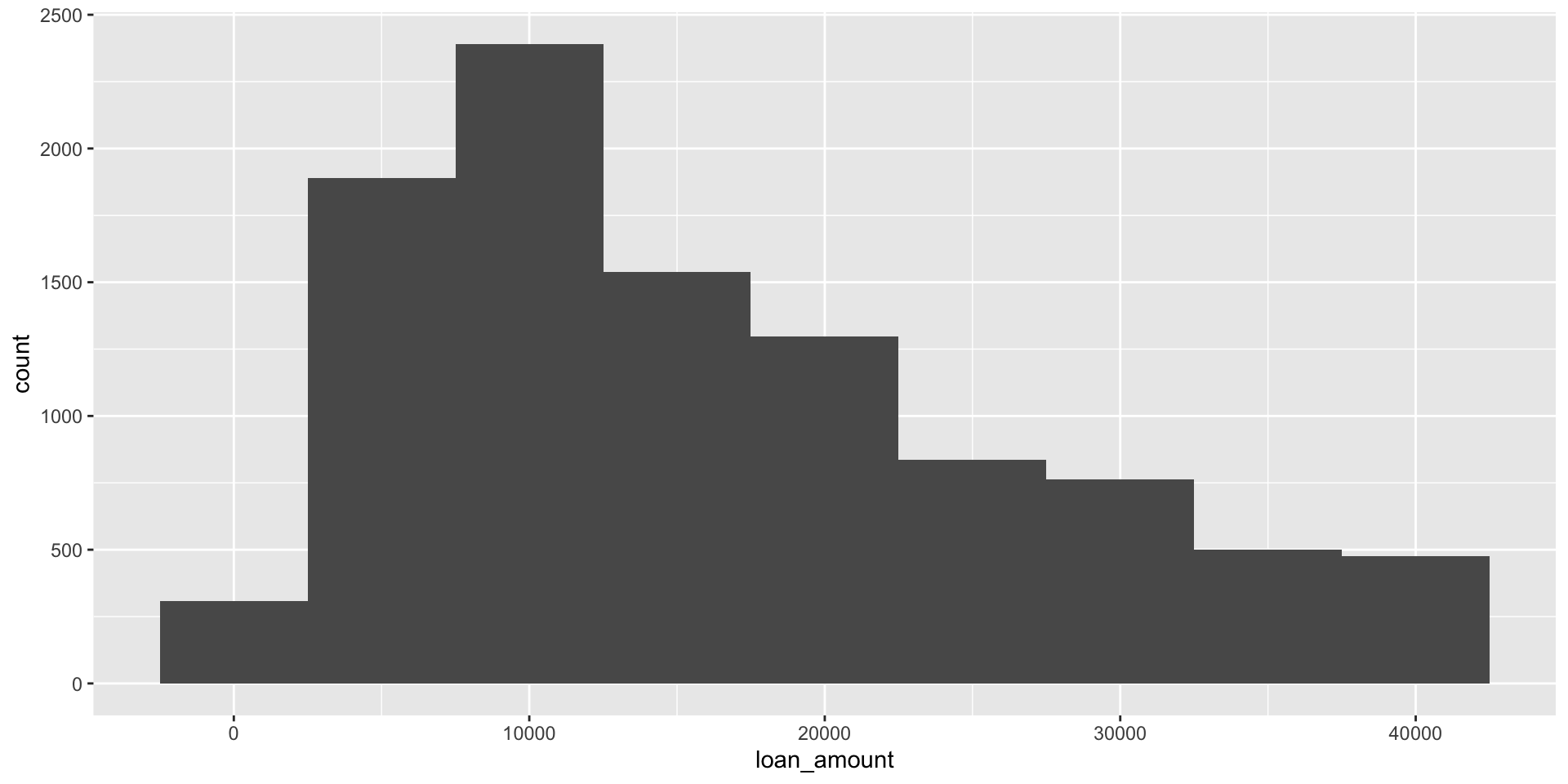
Histograms and binwidth
binwidth = 20000
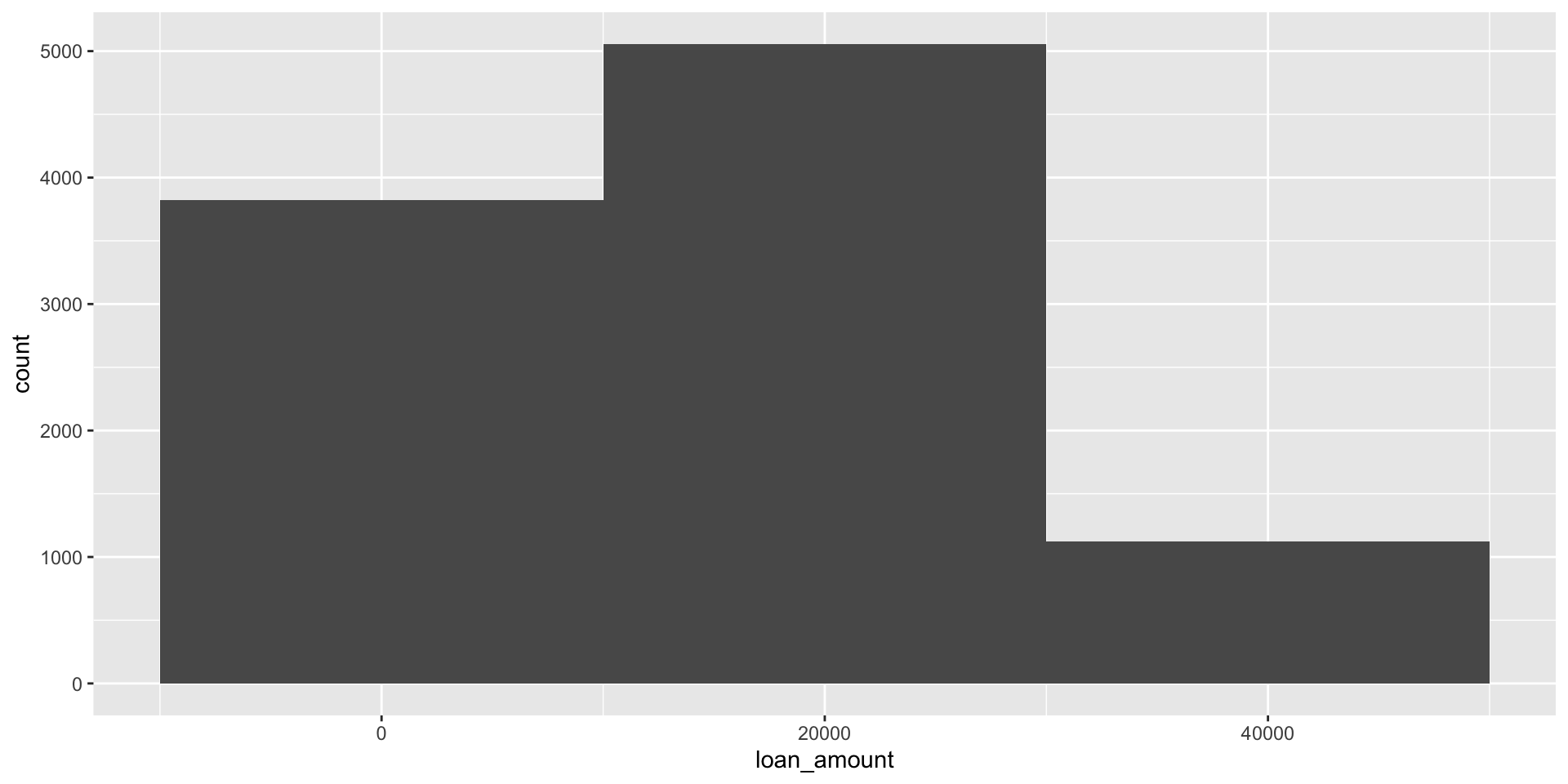
Customizing histograms
Fill with a categorical variable
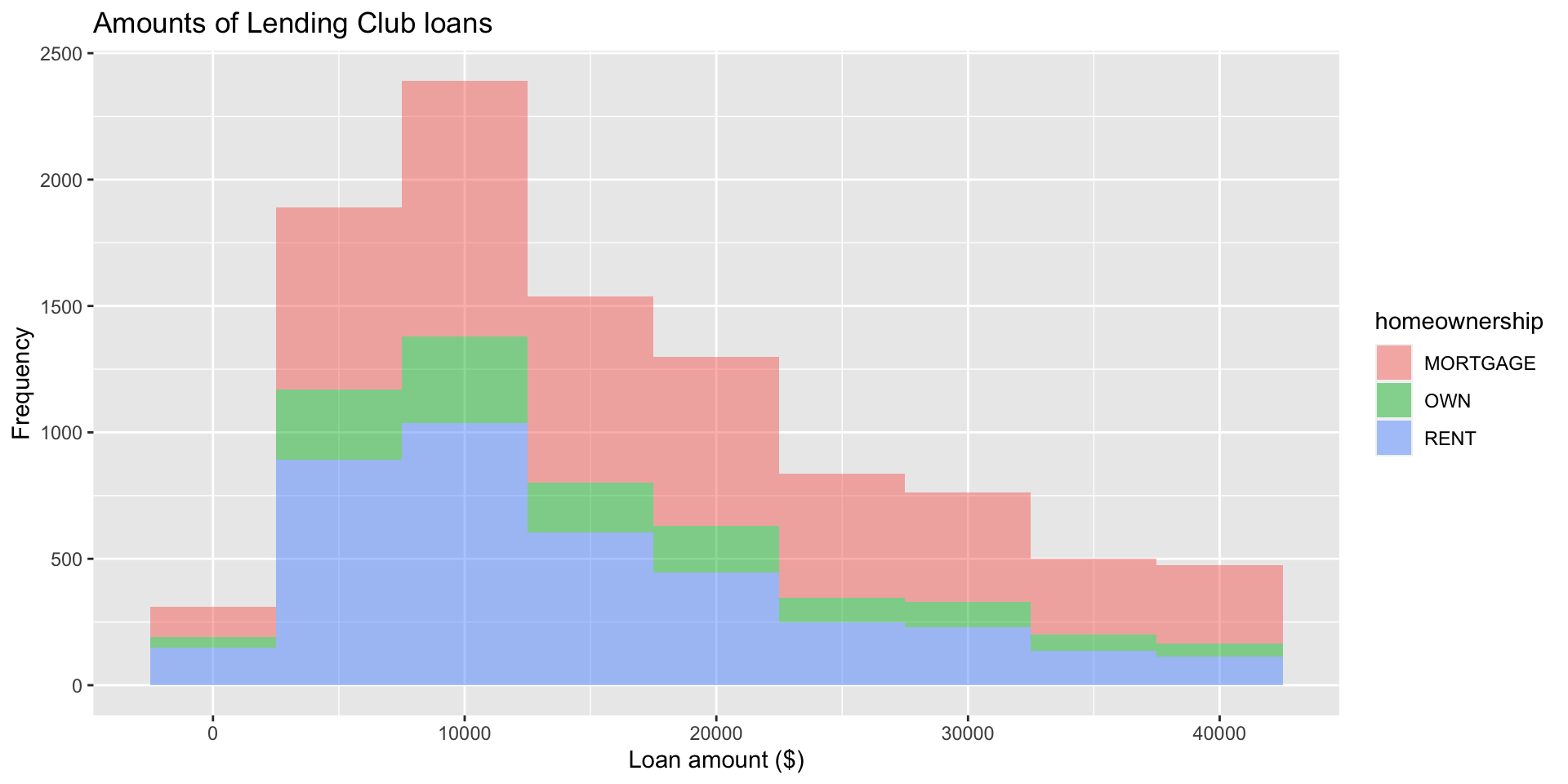
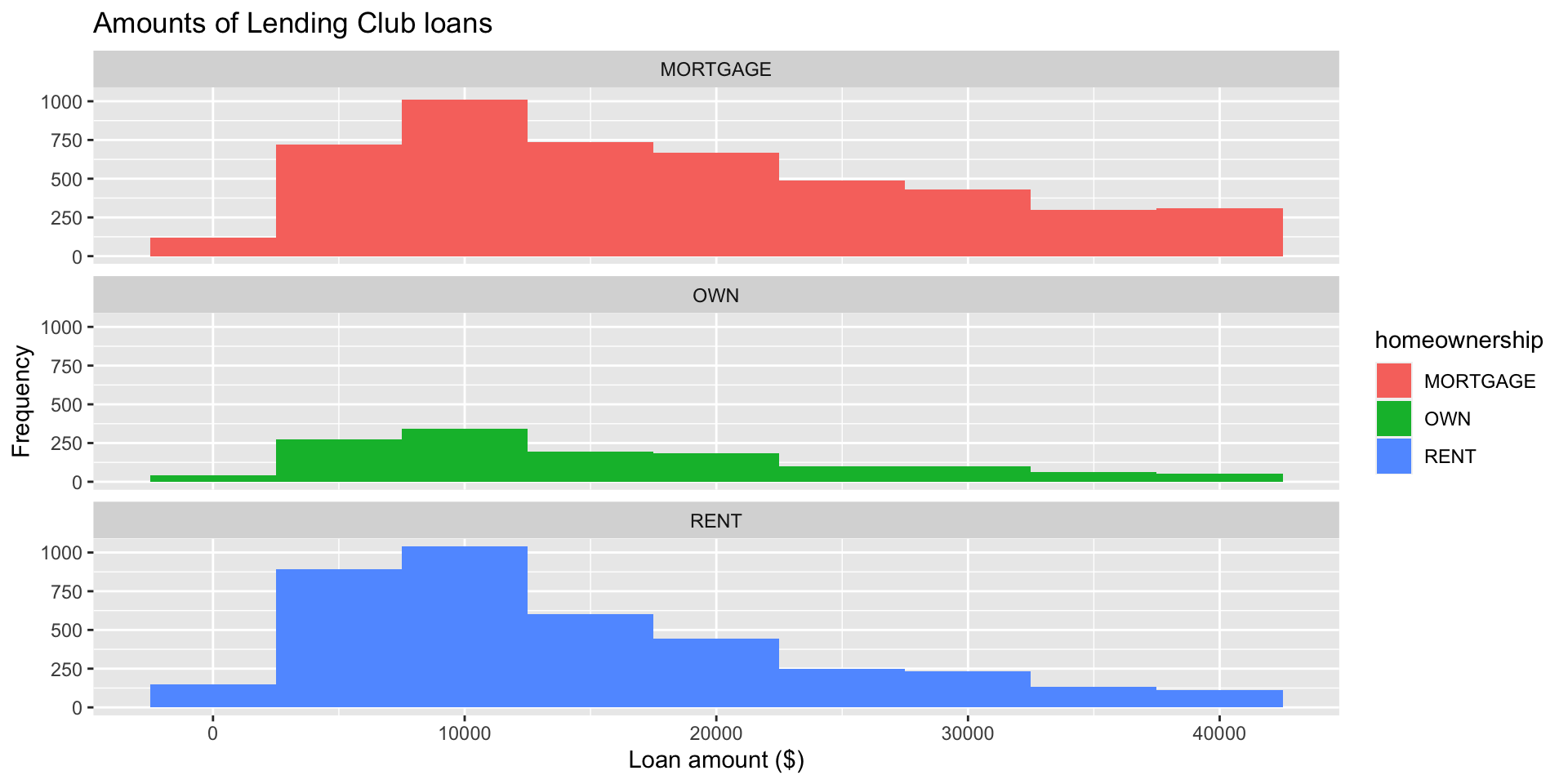
Facet with a categorical variable
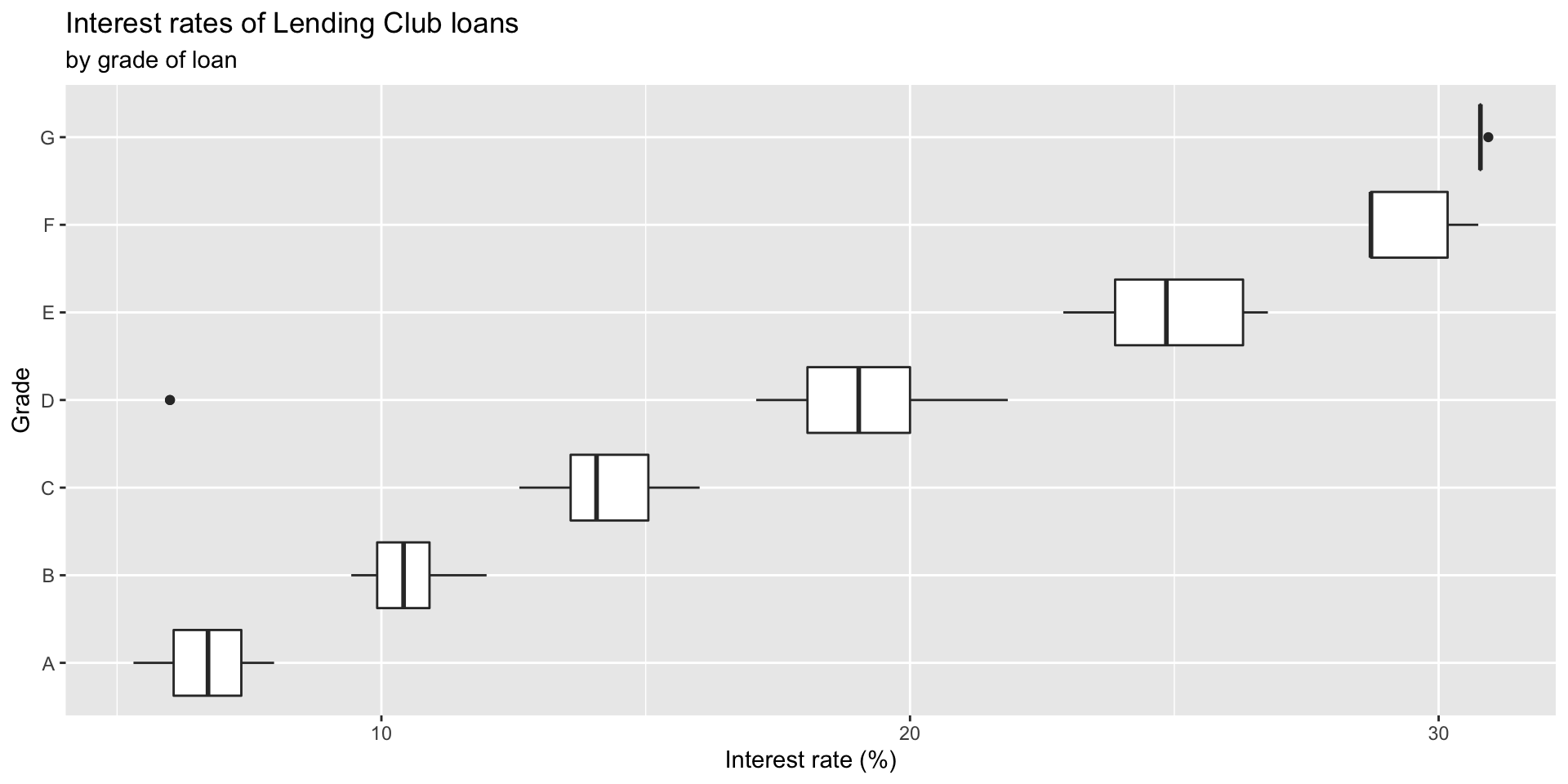
Box plot
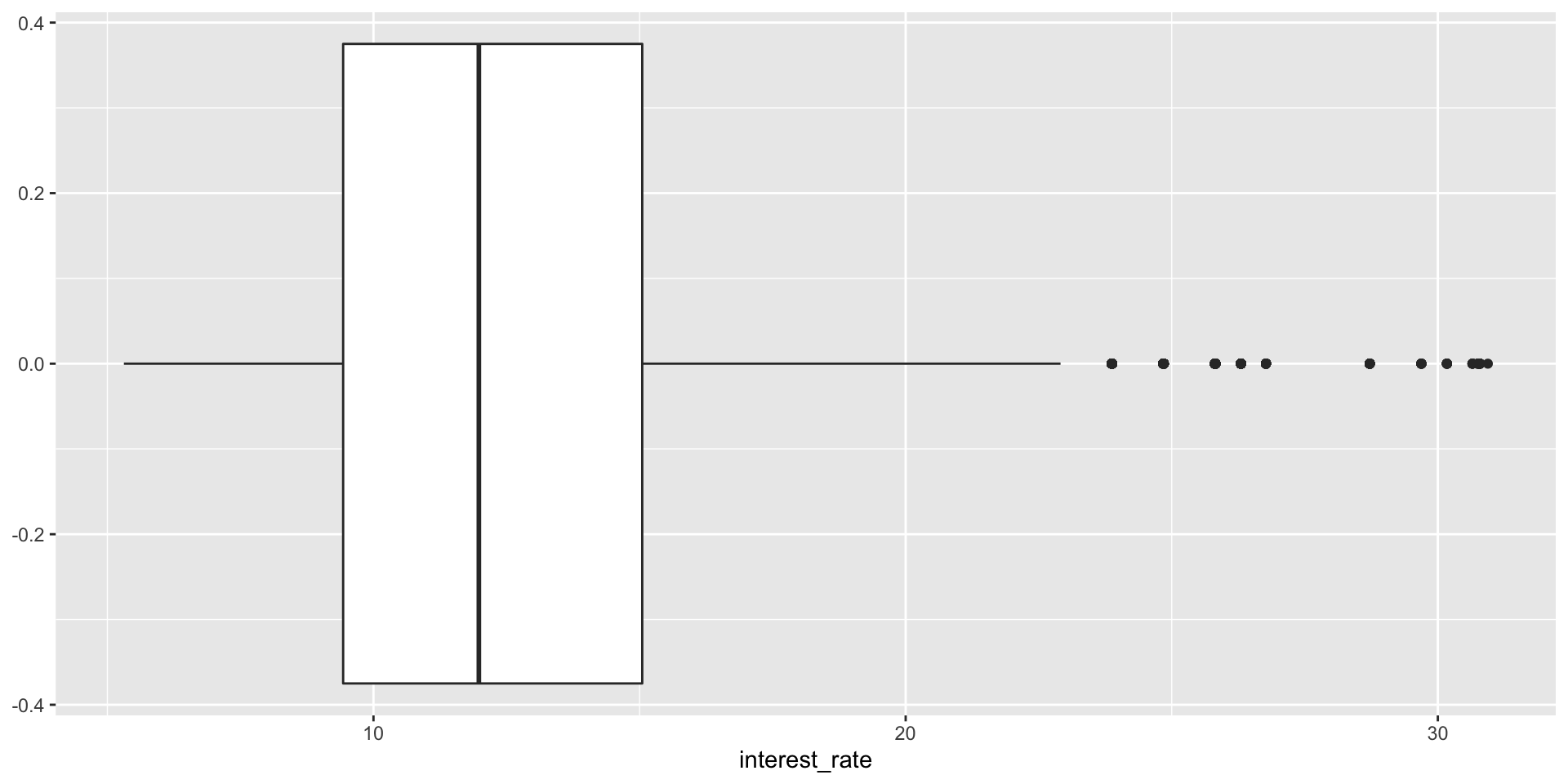
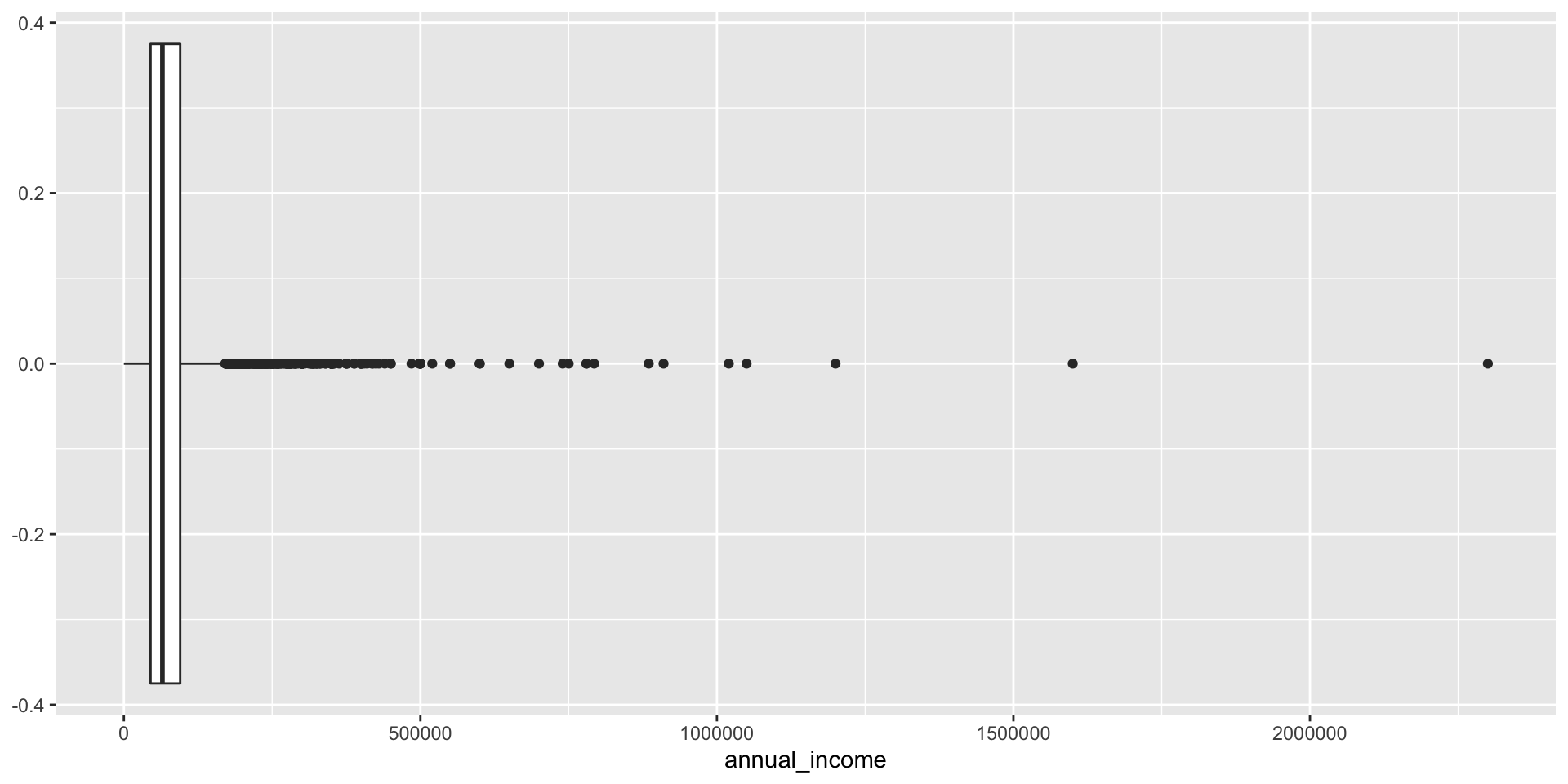
Box plot and outliers
Adding a categorical variable
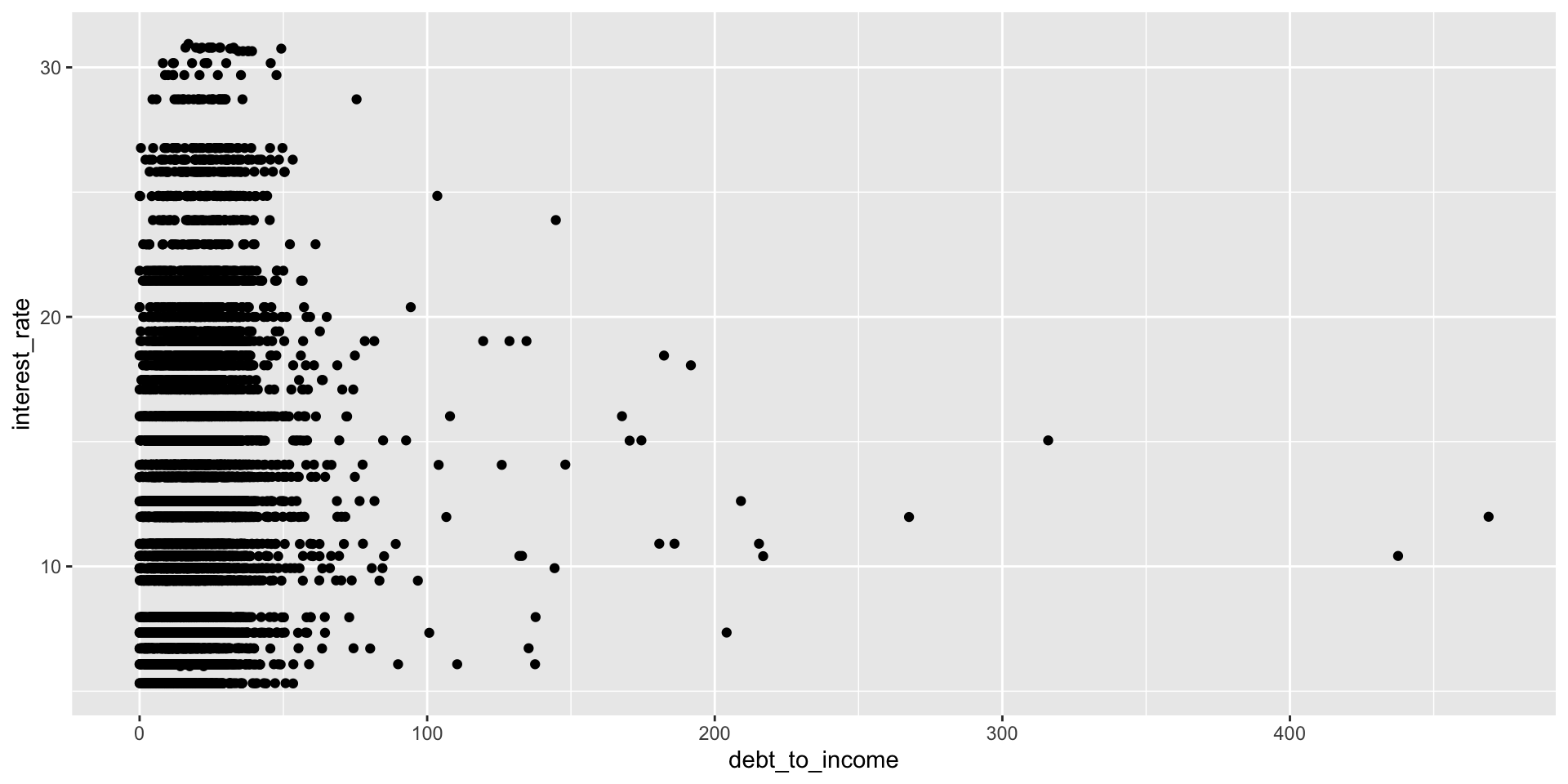
Scatterplot
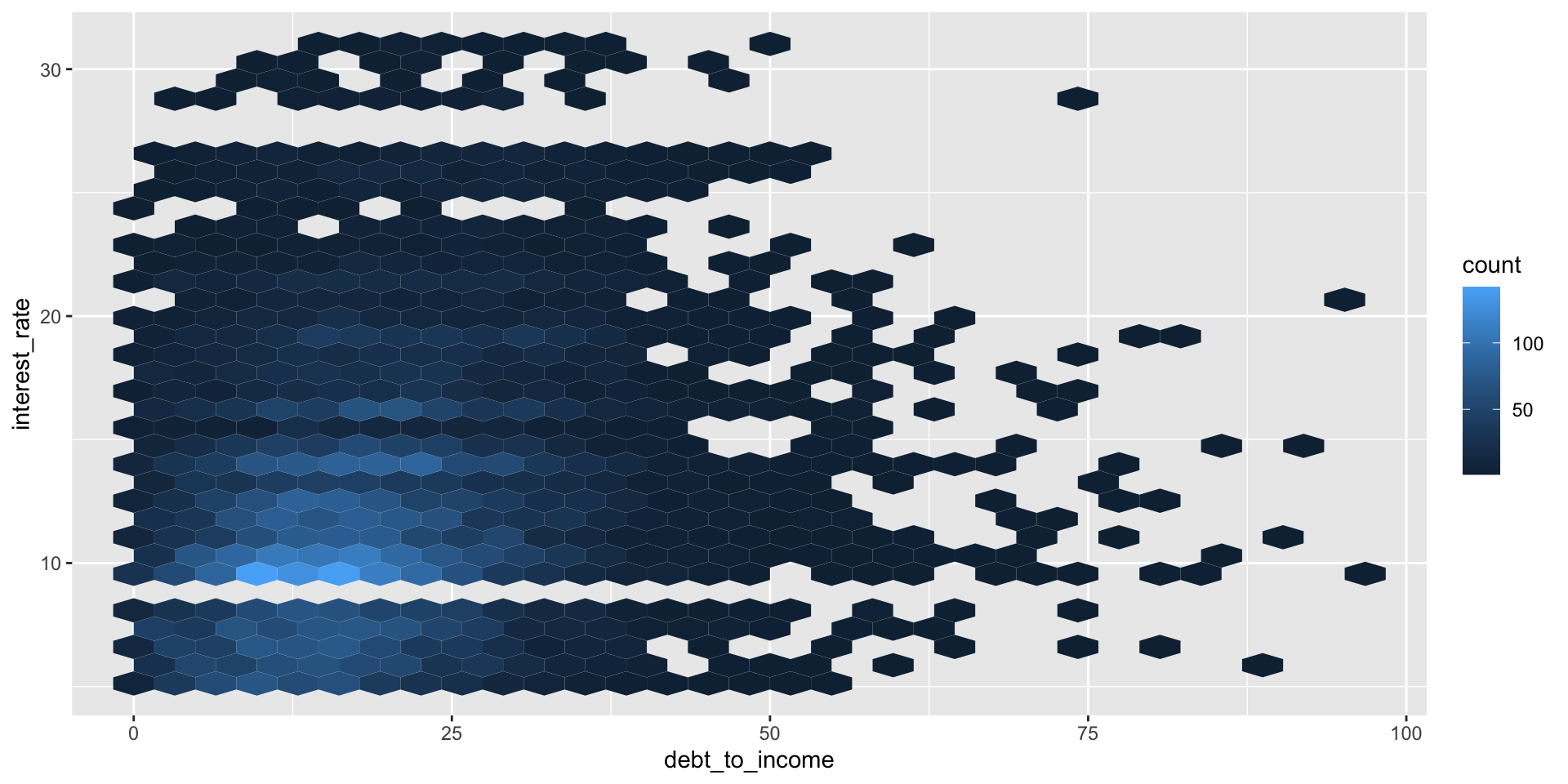
Hex plot
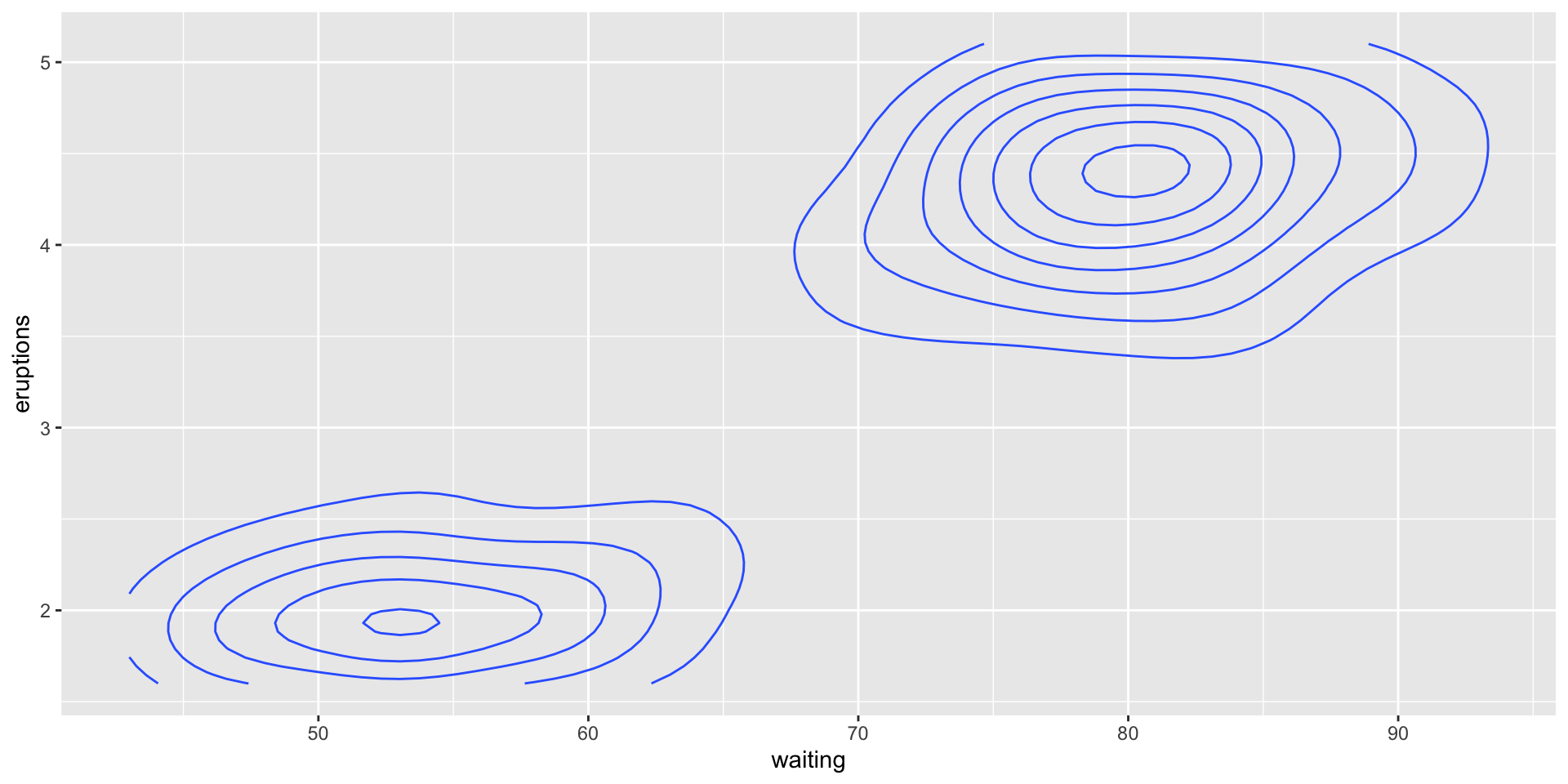
Contour plot
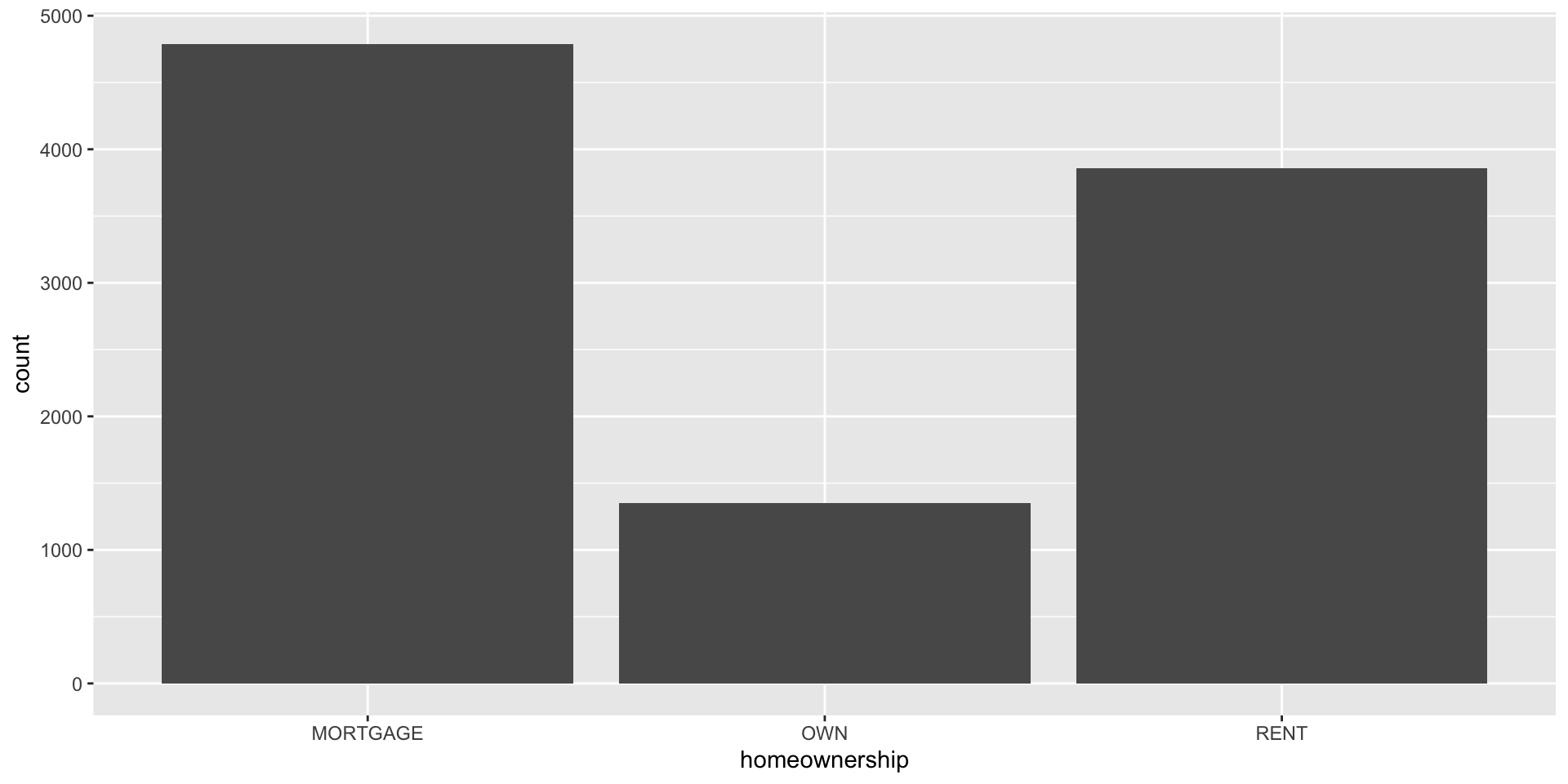
Bar plot
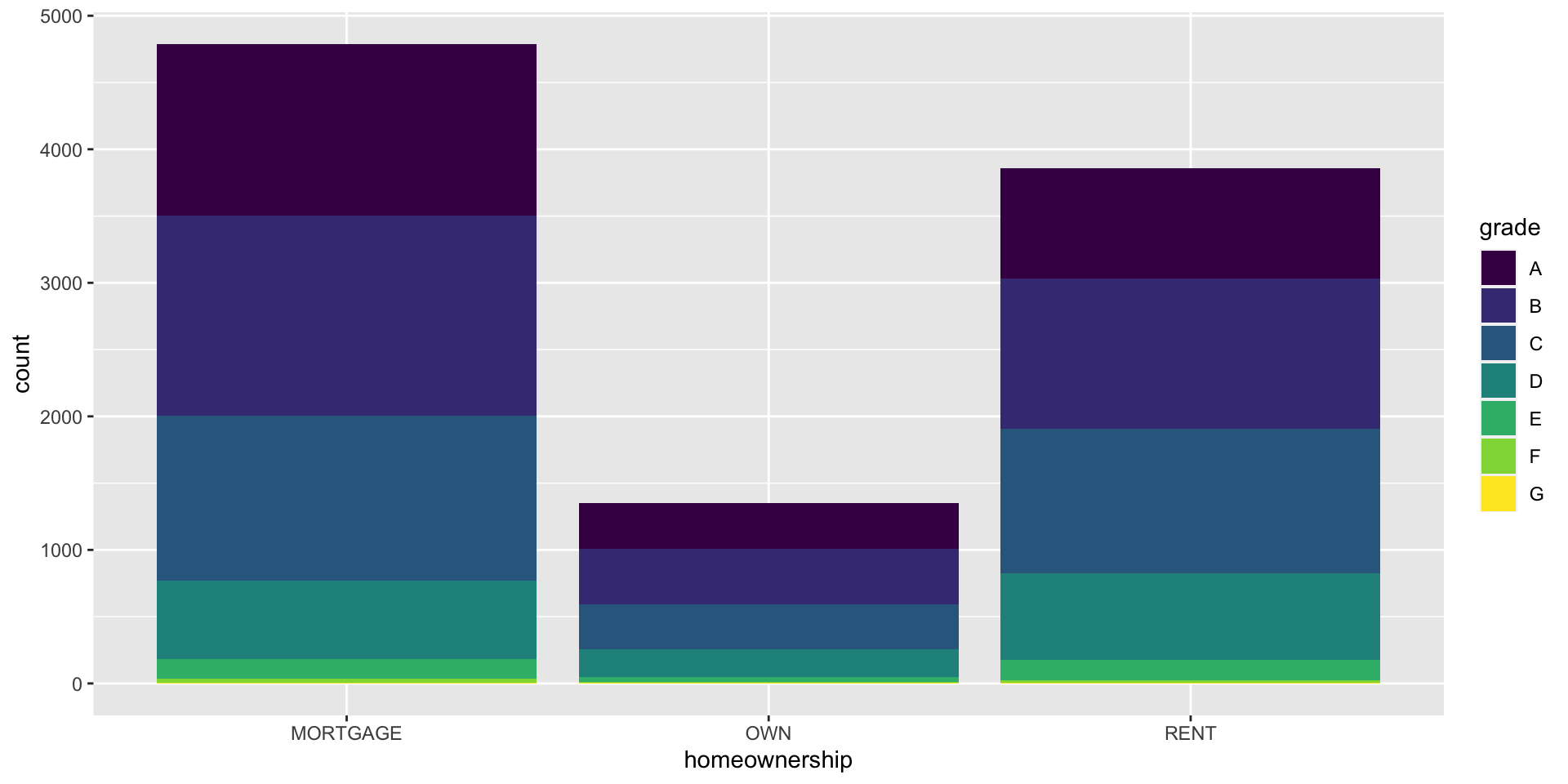
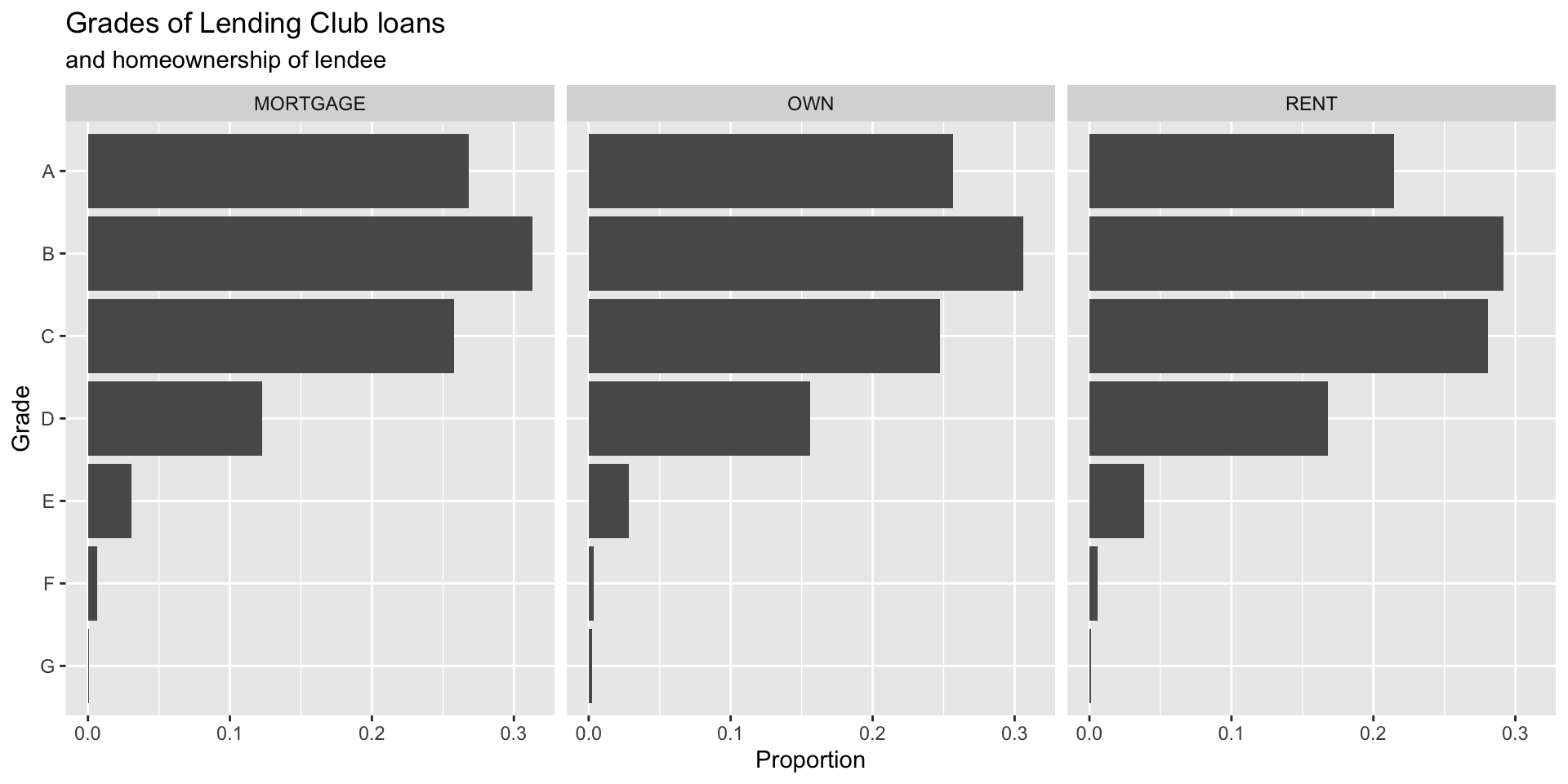
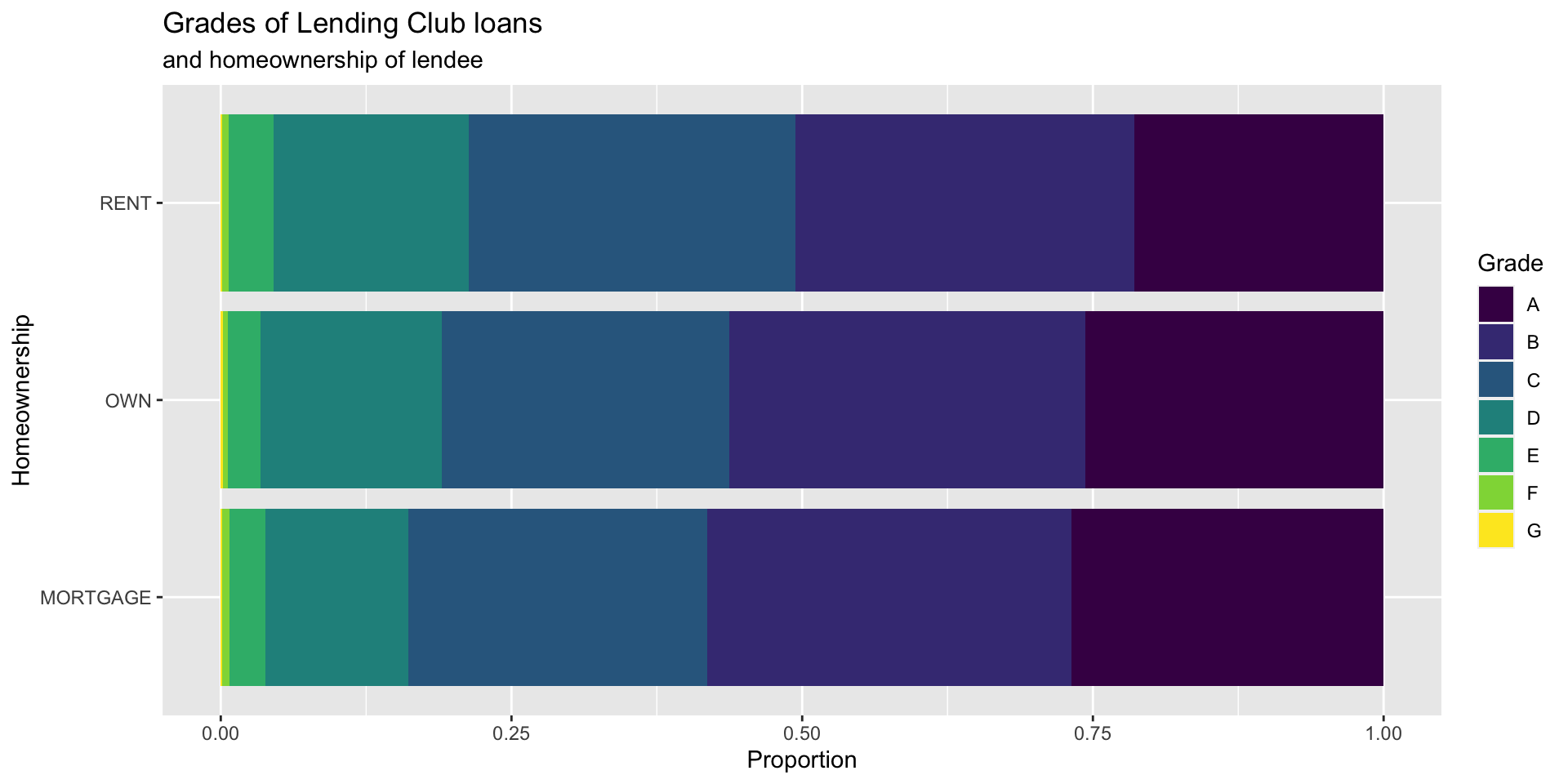
Segmented bar plot
Segmented bar plot
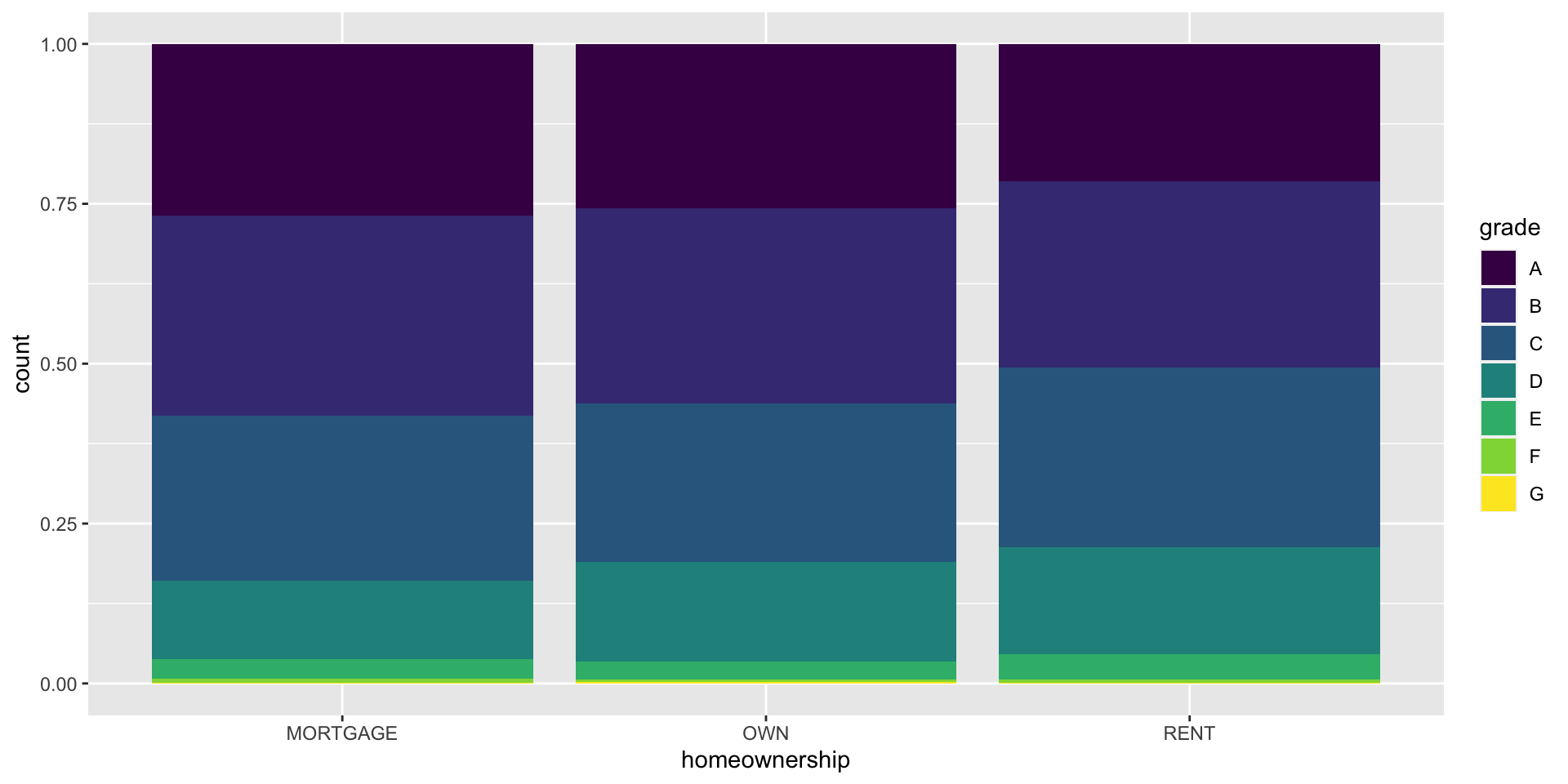
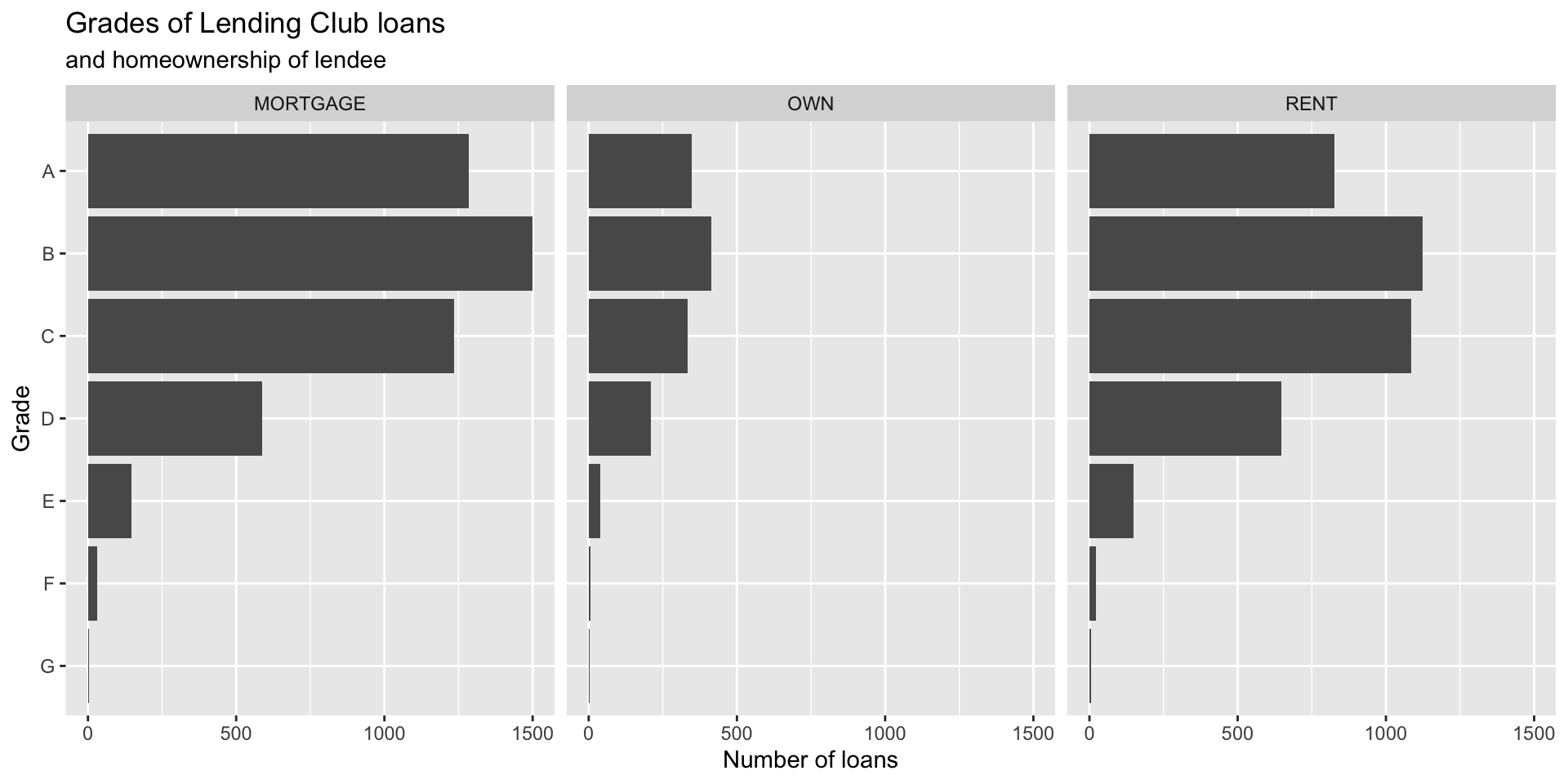
Which bar plot is a more useful representation for visualizing the relationship between homeownership and grade?
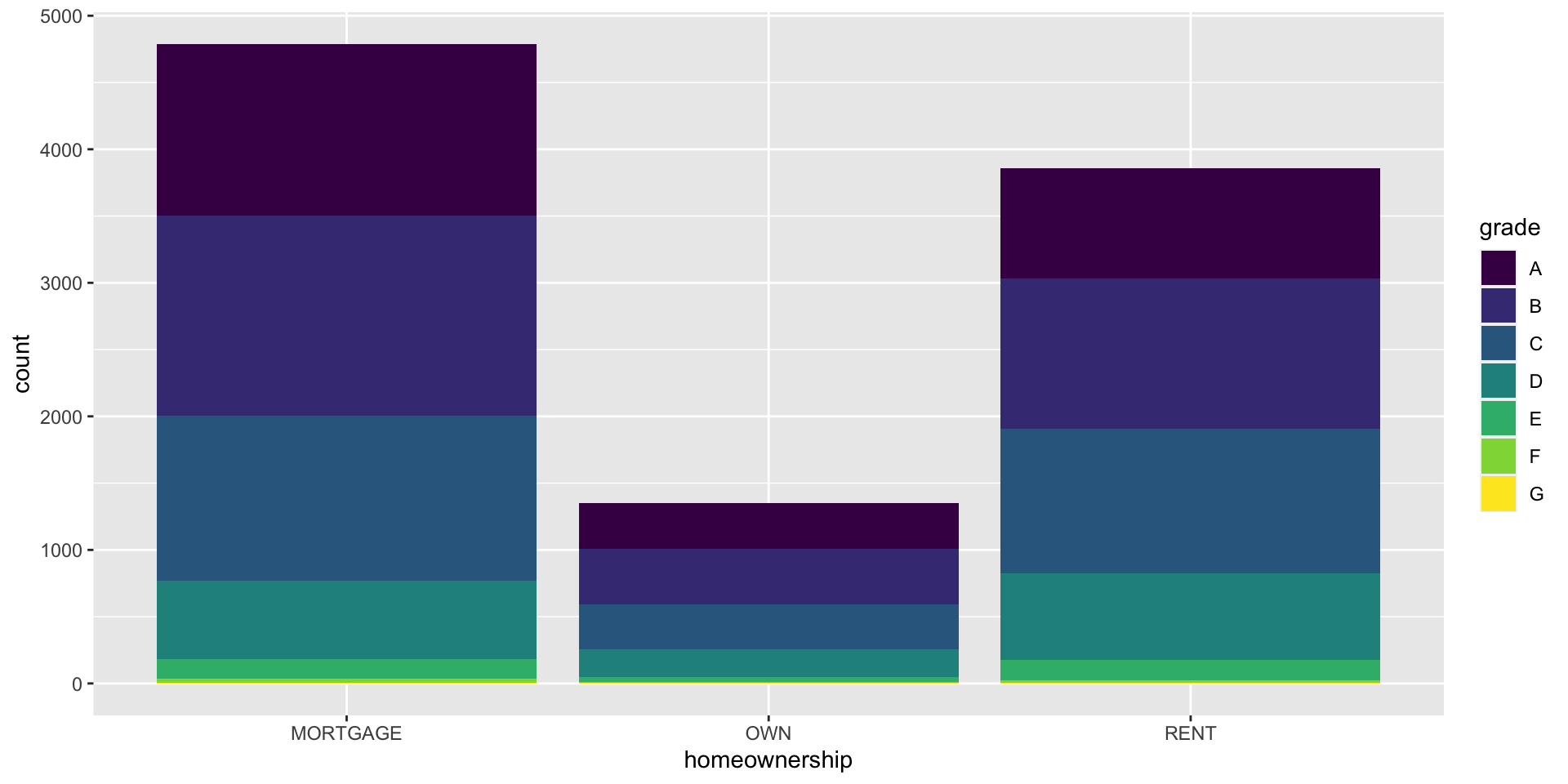
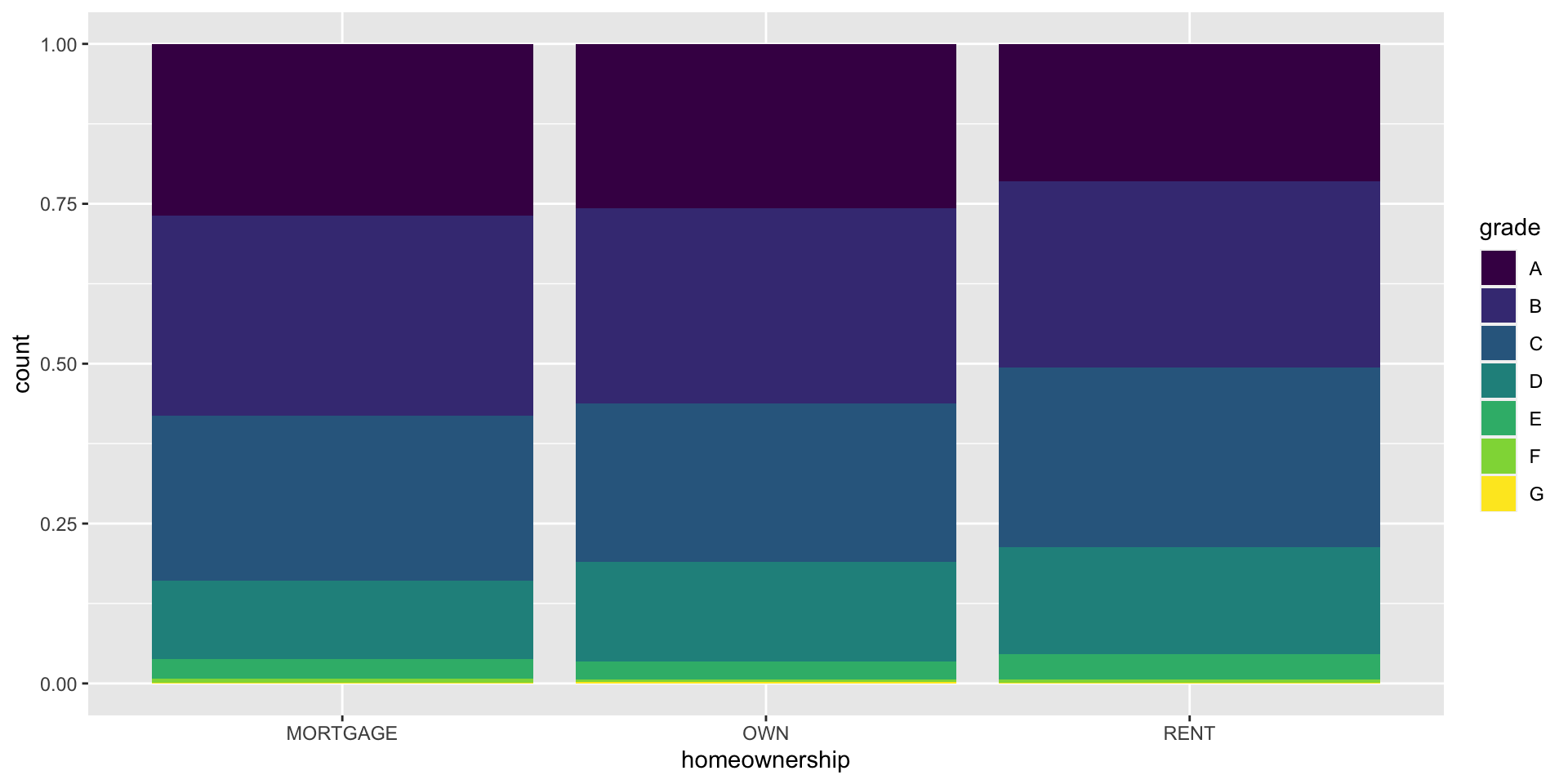
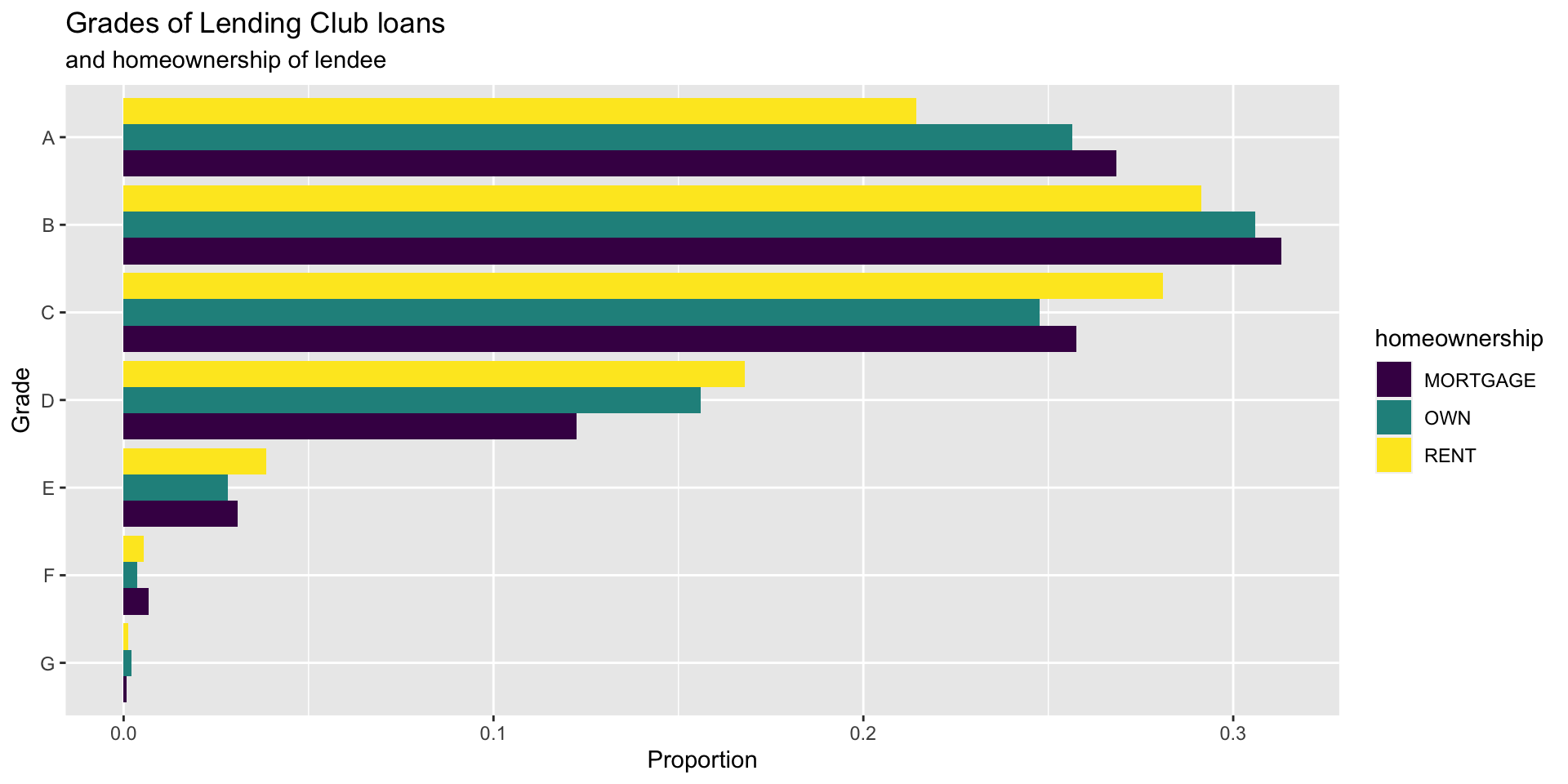
Customizing bar plots
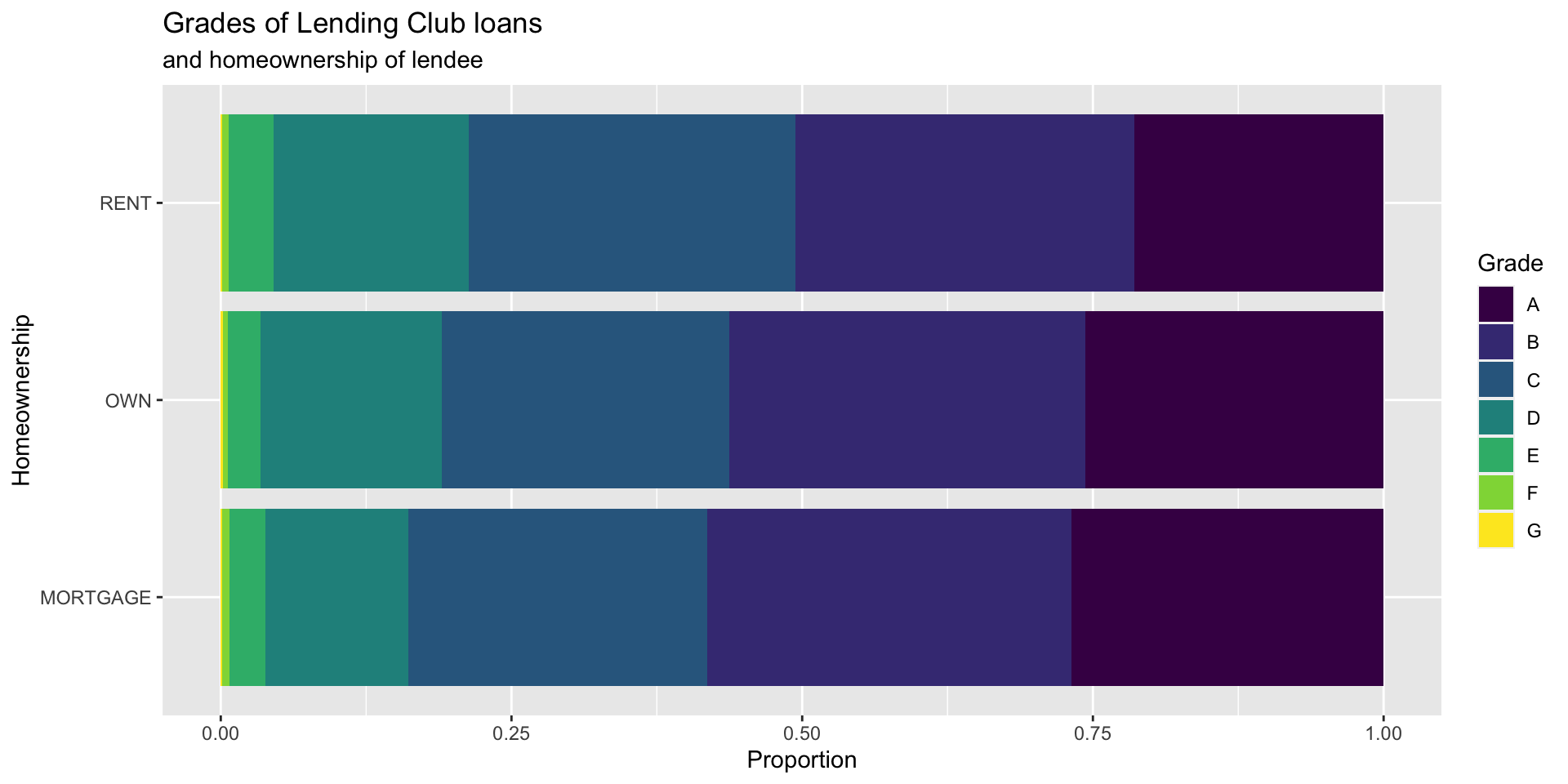
Customizing bar plots
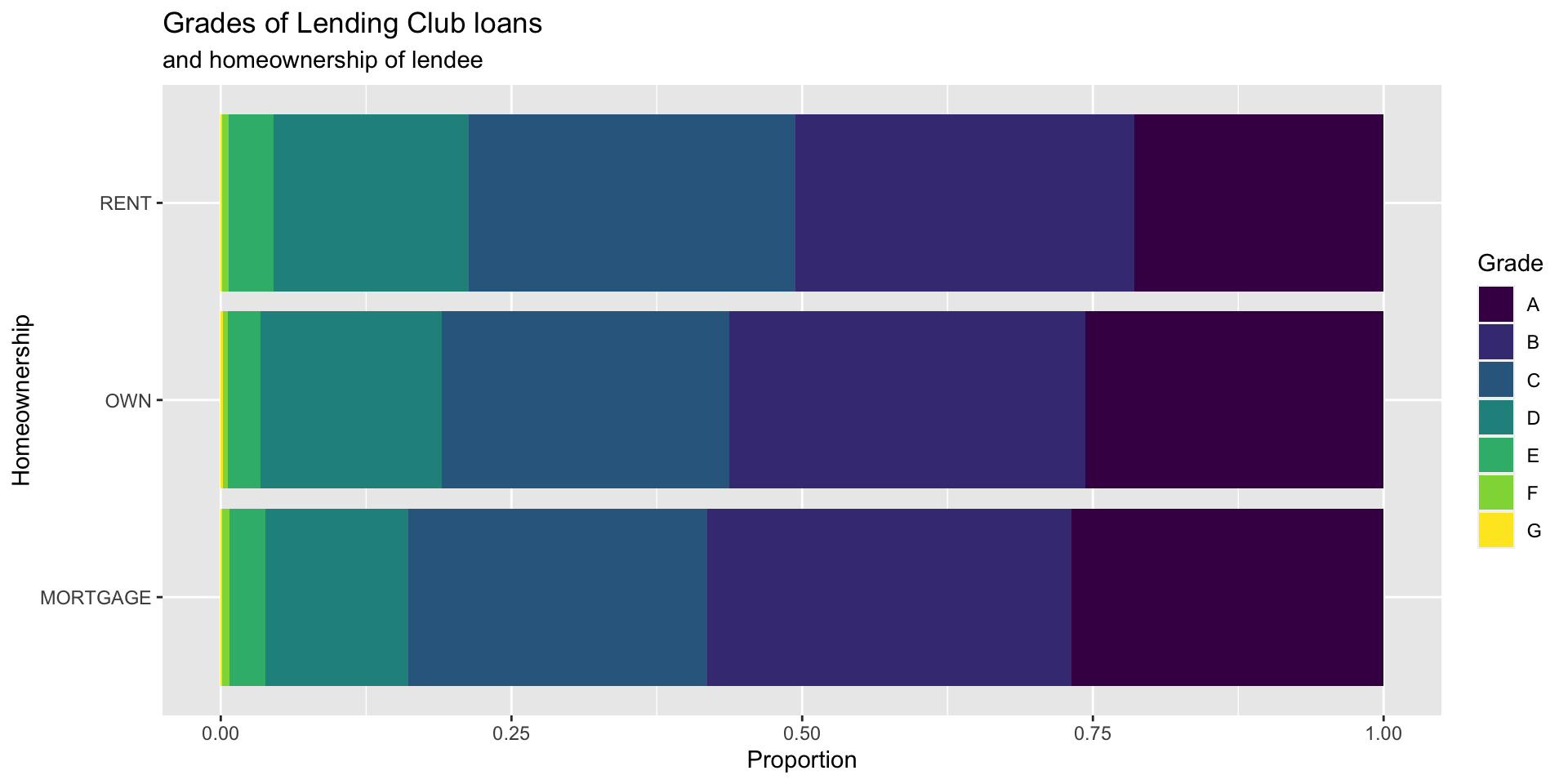
Customizing bar plots
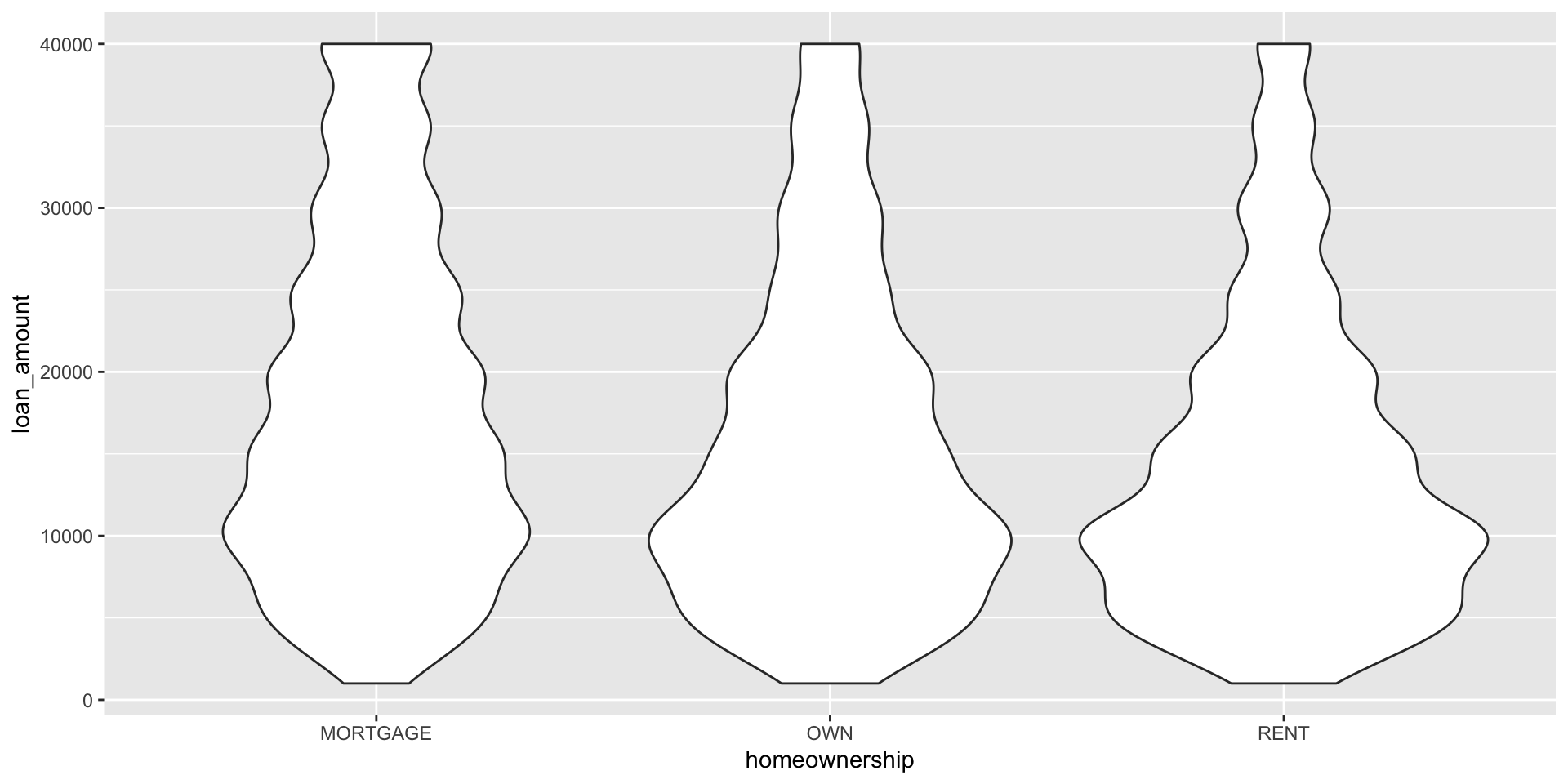
Violin plots
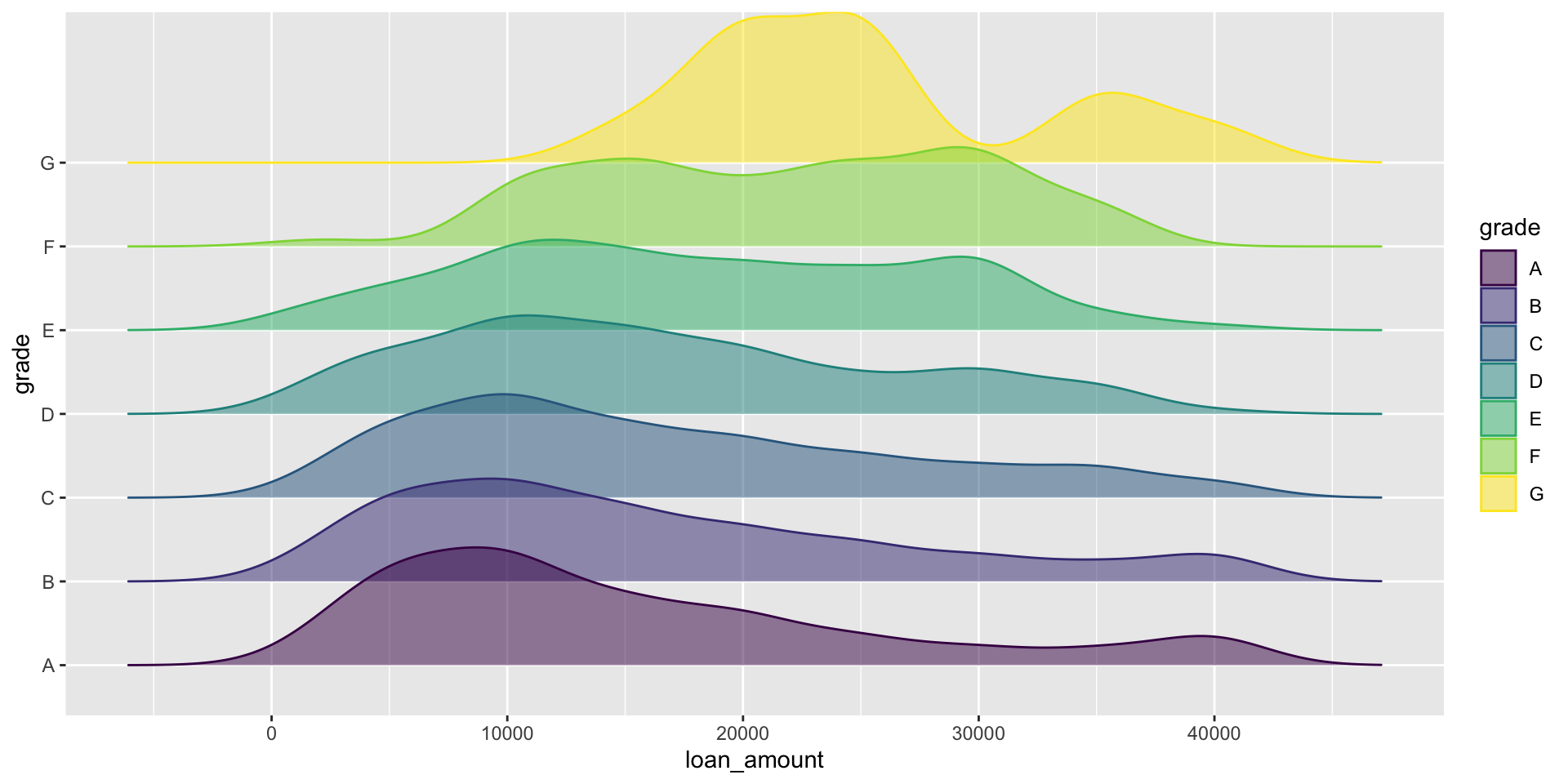
Ridge plots
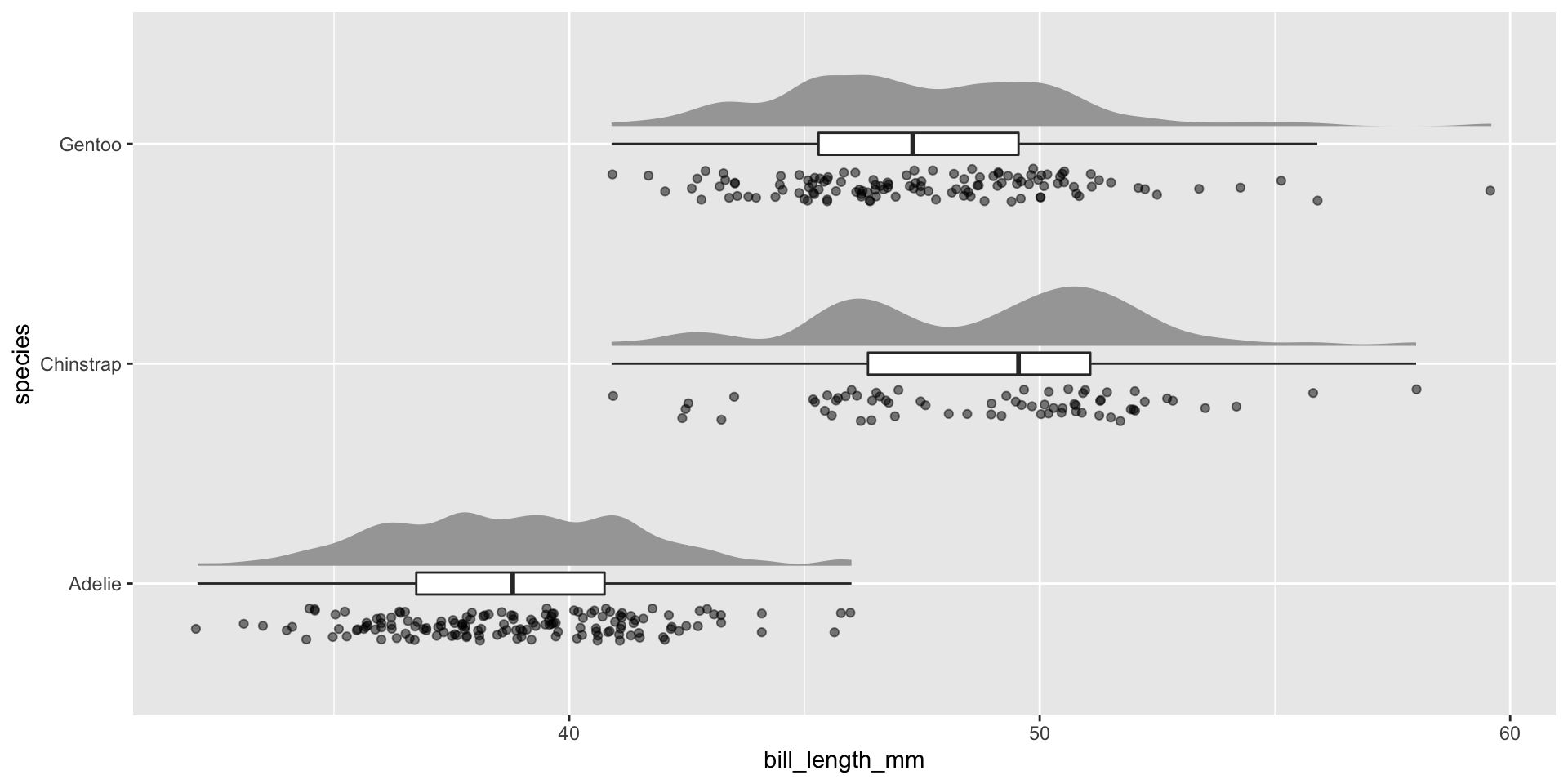
Raincloud plots
library(ggdist)
library(gghalves)
ggplot(penguins, aes(species, bill_length_mm)) +
ggdist::stat_halfeye(adjust = .5, width = .3, .width = 0, justification = -.3, point_colour = NA) +
geom_boxplot(width = .1, outlier.shape = NA) +
gghalves::geom_half_point(side = "l", range_scale = .4, alpha = .5) +
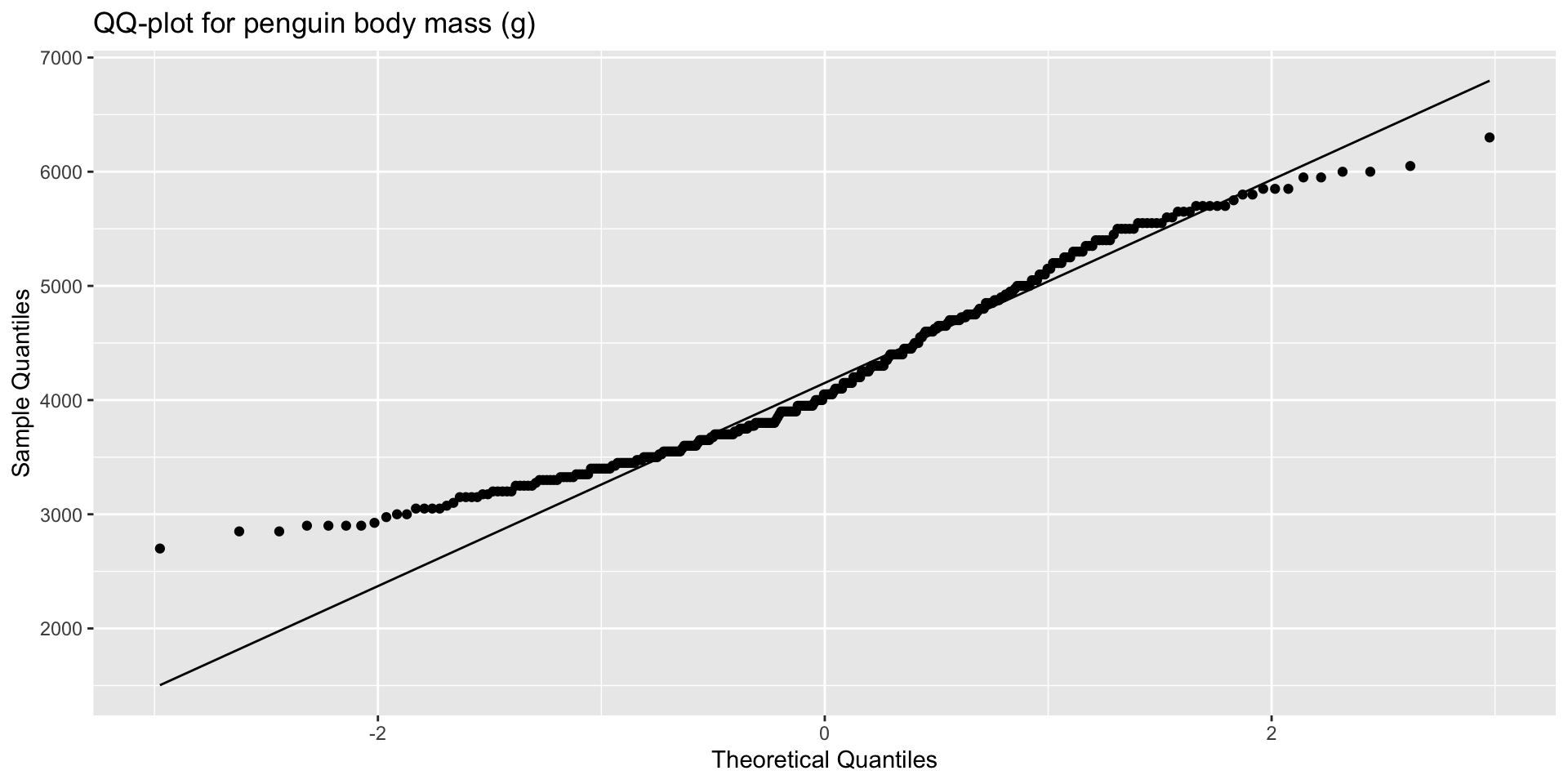
coord_flip()QQ-plots
Determines if data conform to a theoretical distribution.
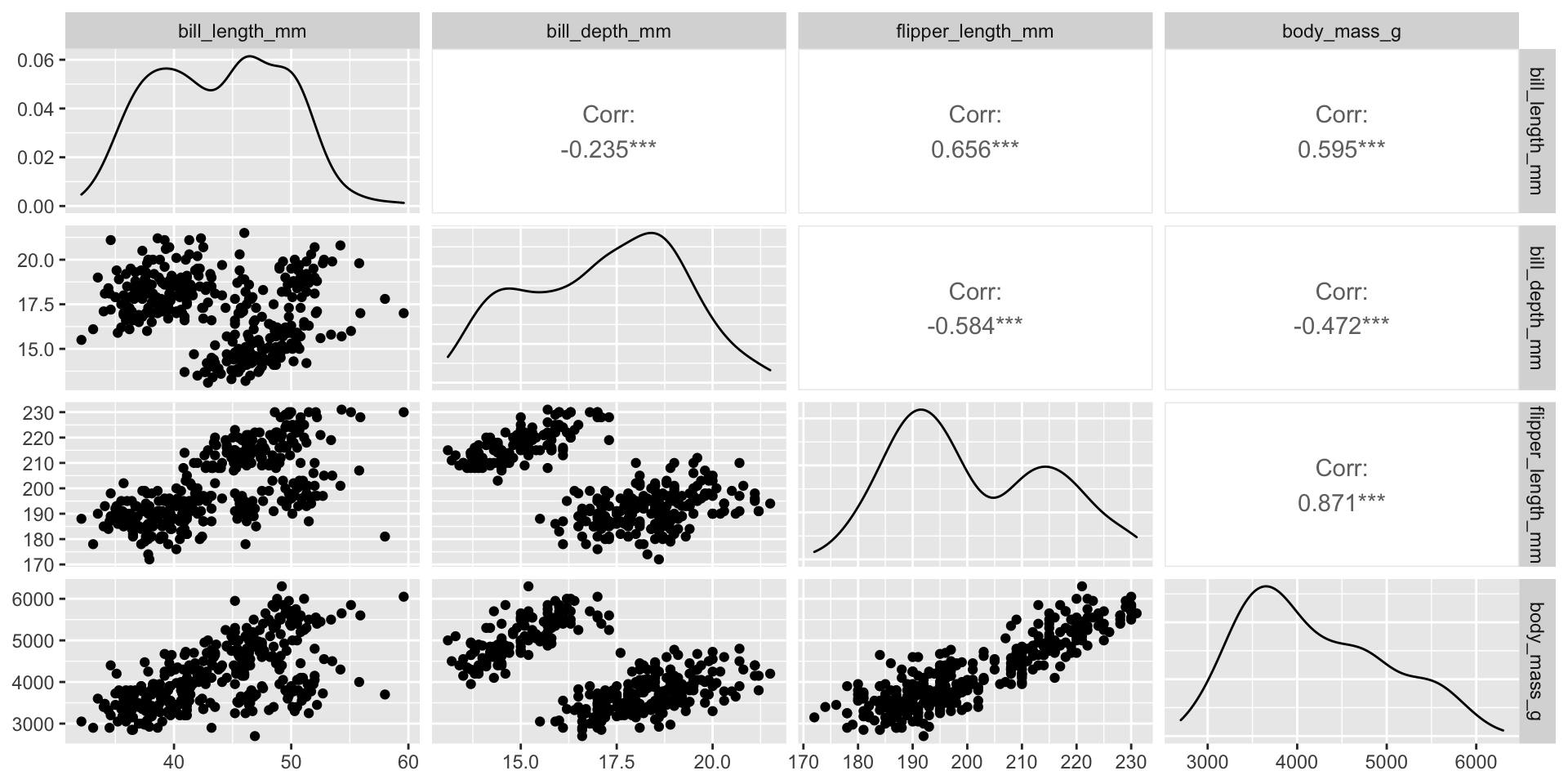
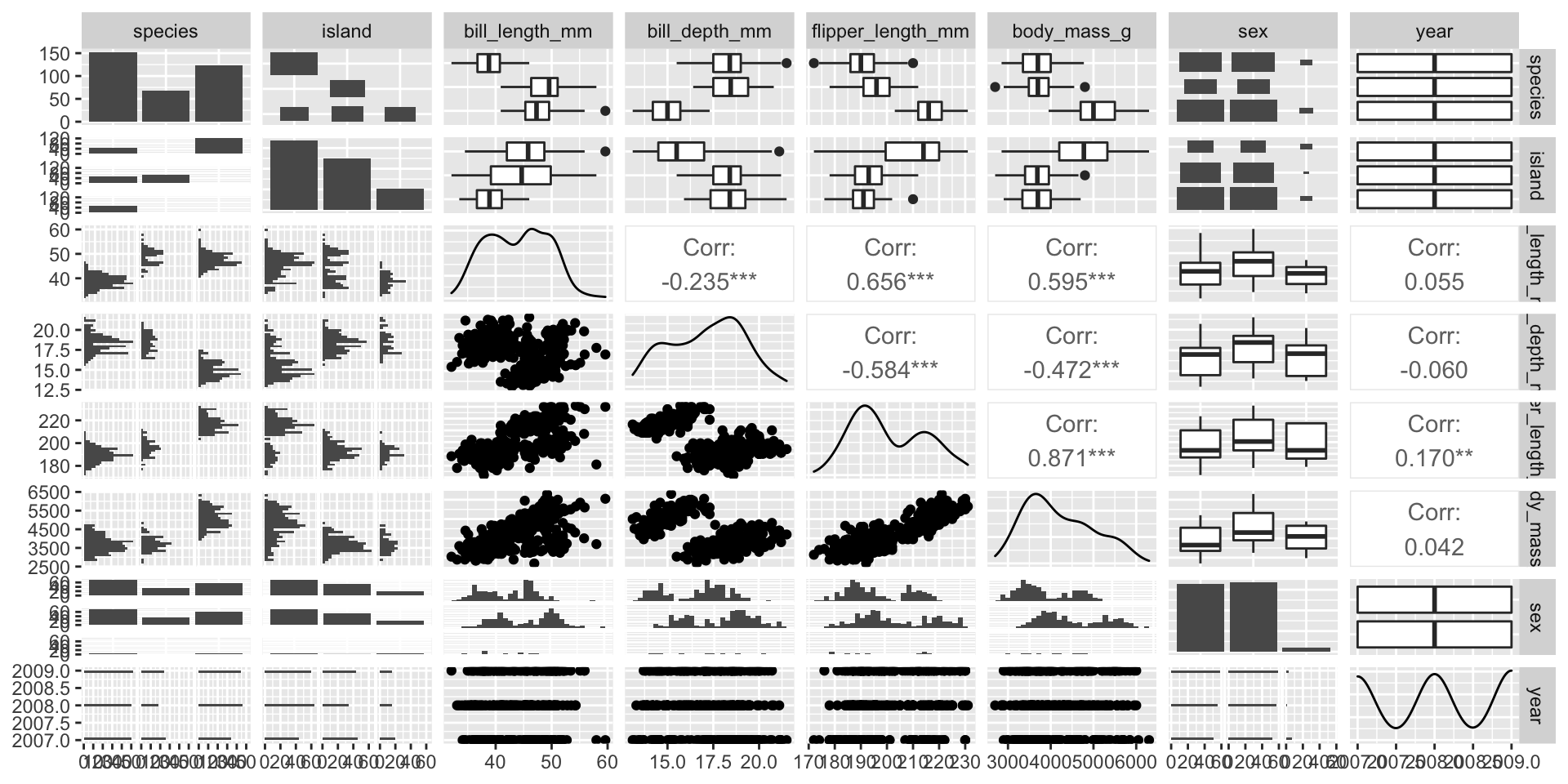
Pair plots
- Scatterplot for each pair of variables.
- Measures of correlation
Über Pair plot
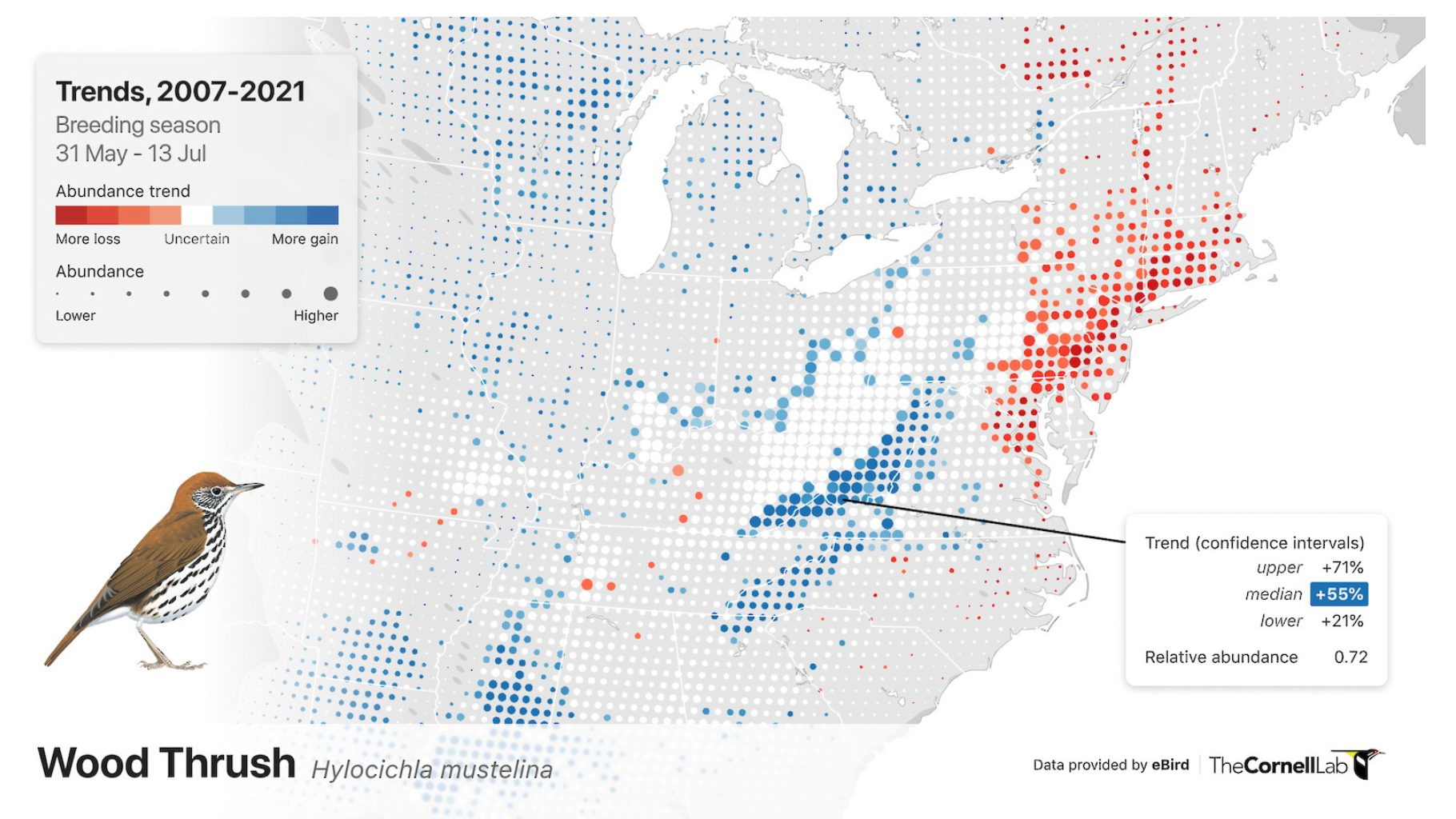
Visualizing spatial data
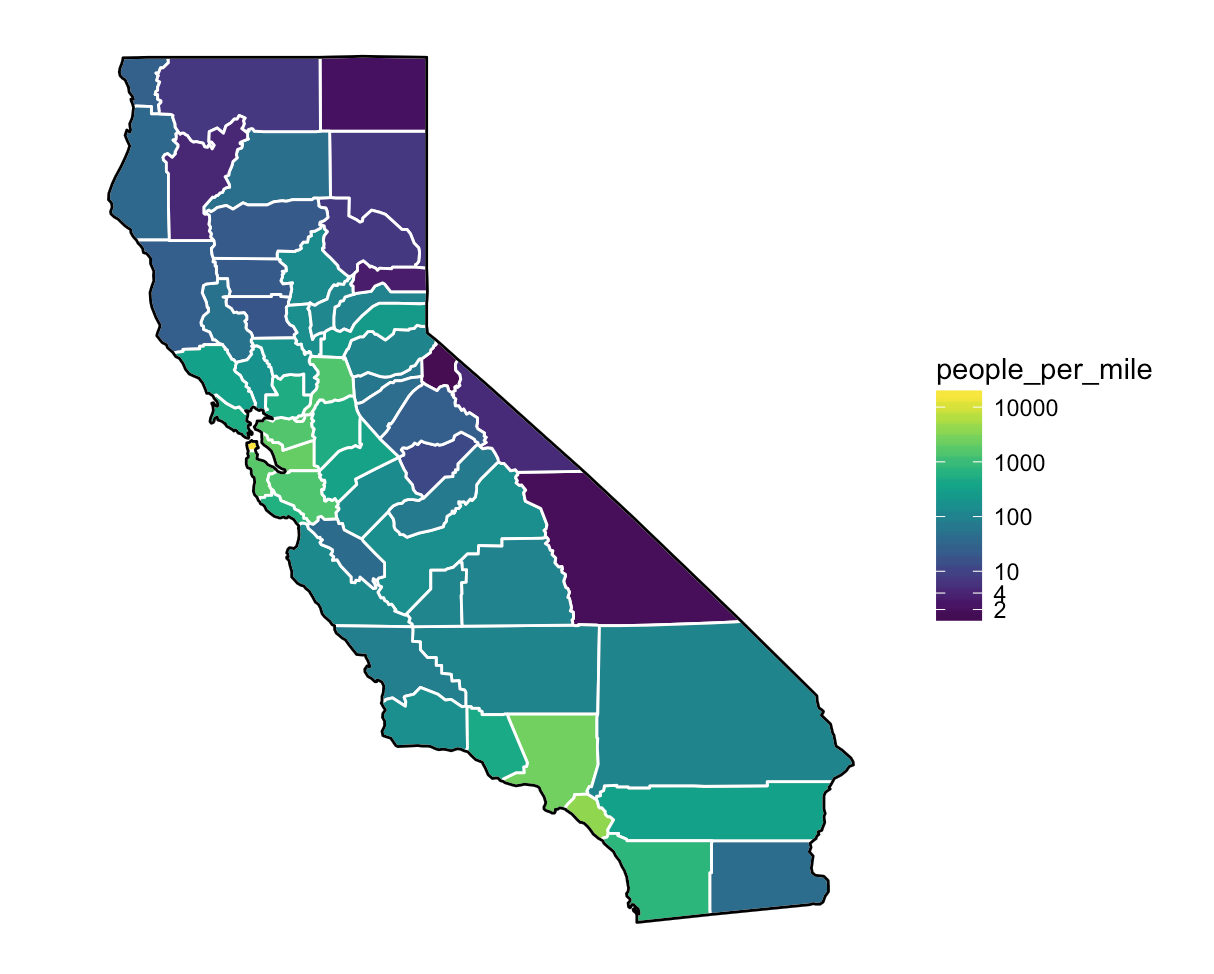
Maps are extremely useful (and intuitive) ways of exploring spatial relationships among variables in our data.
 (
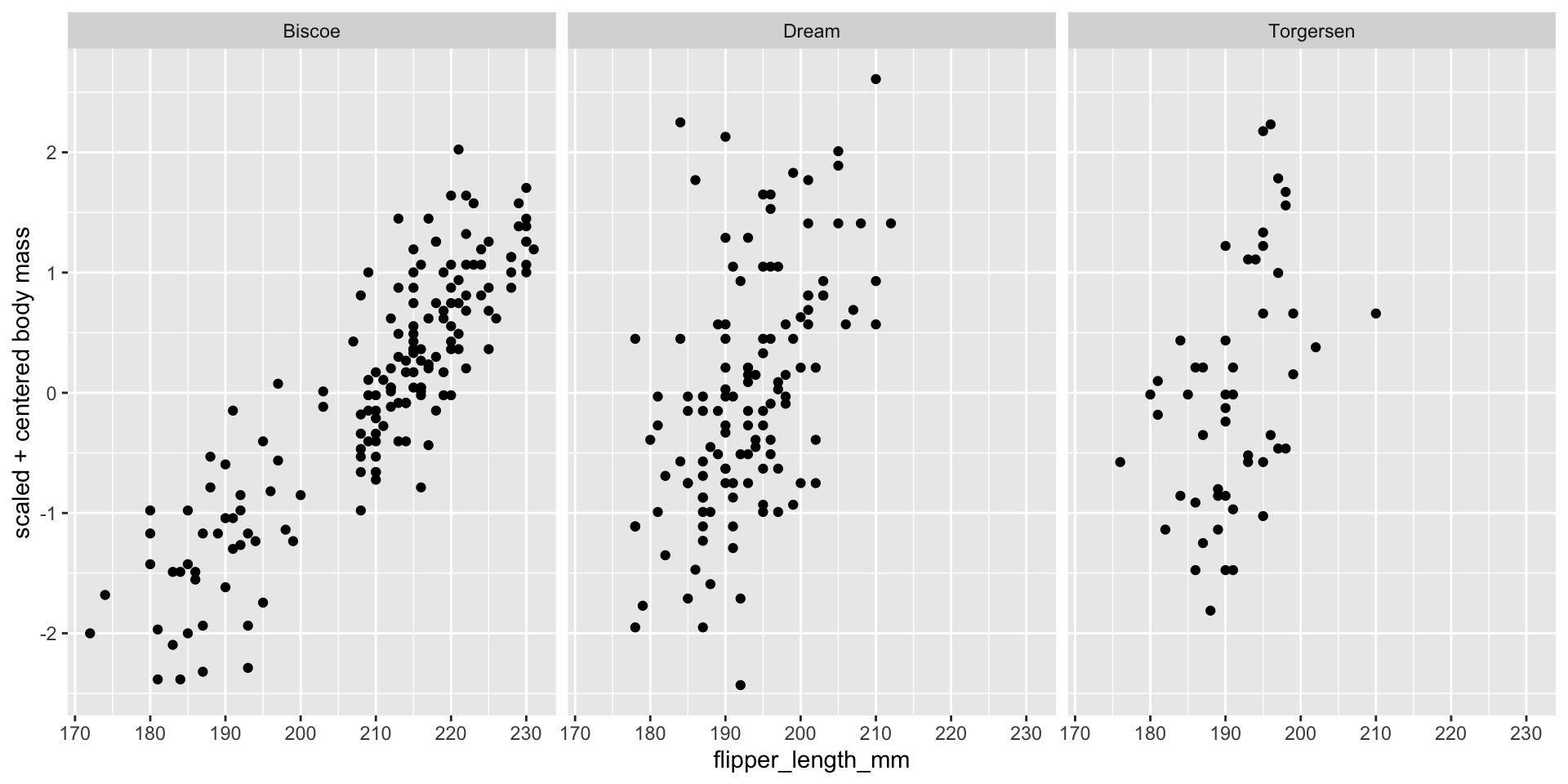
(Standardizations
Standardizations
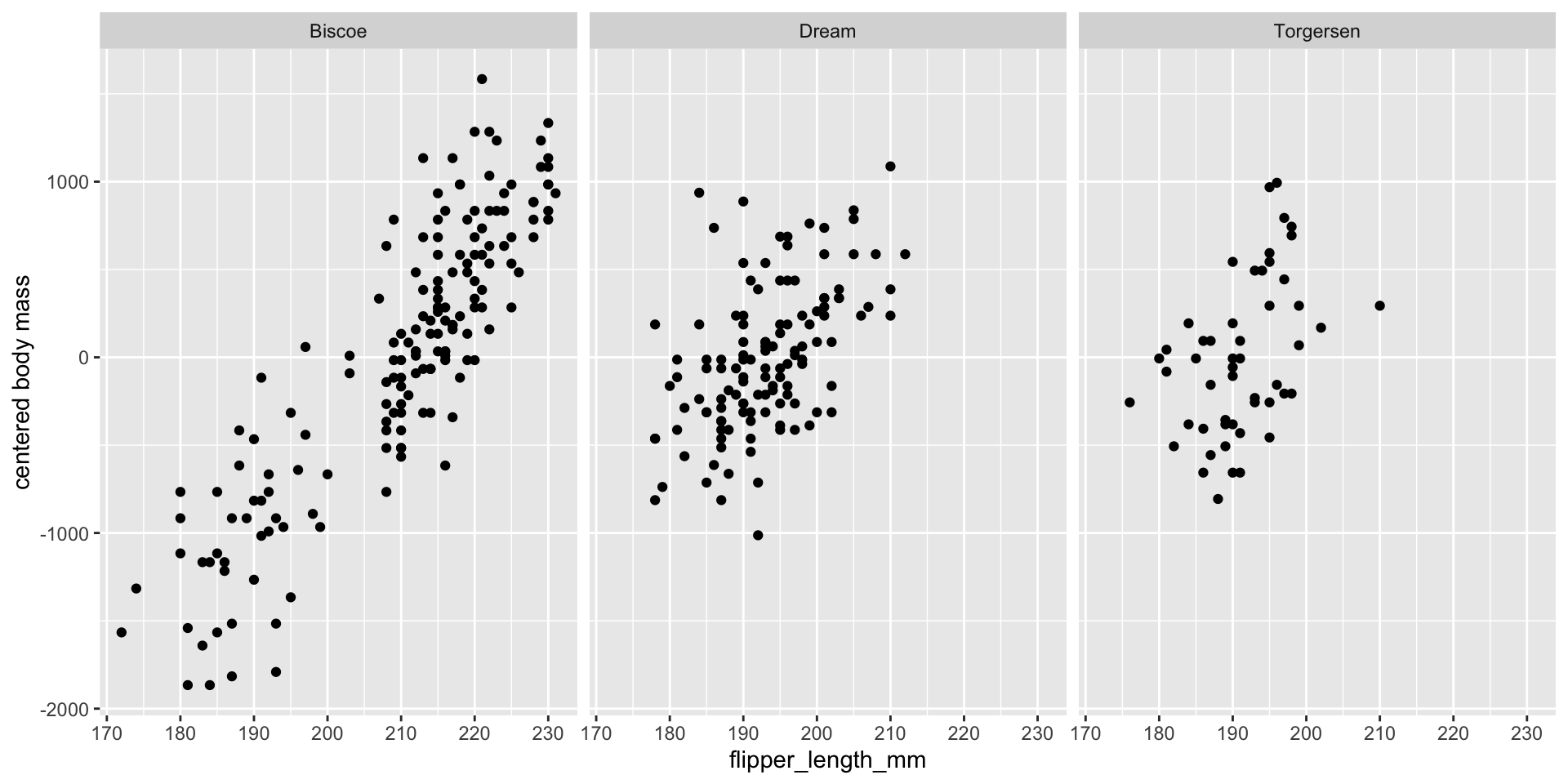
Standardizations
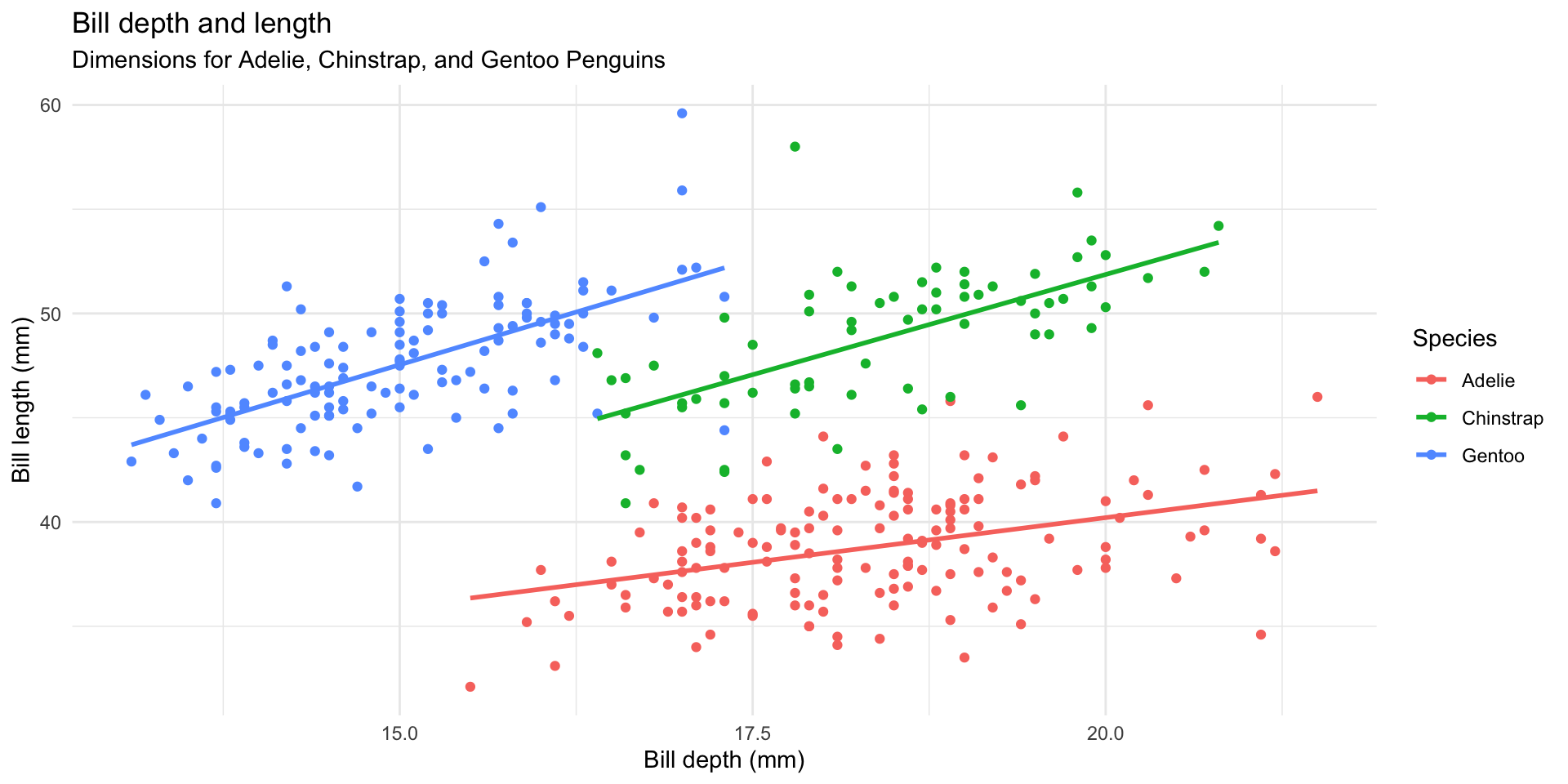
Simpson’s paradox
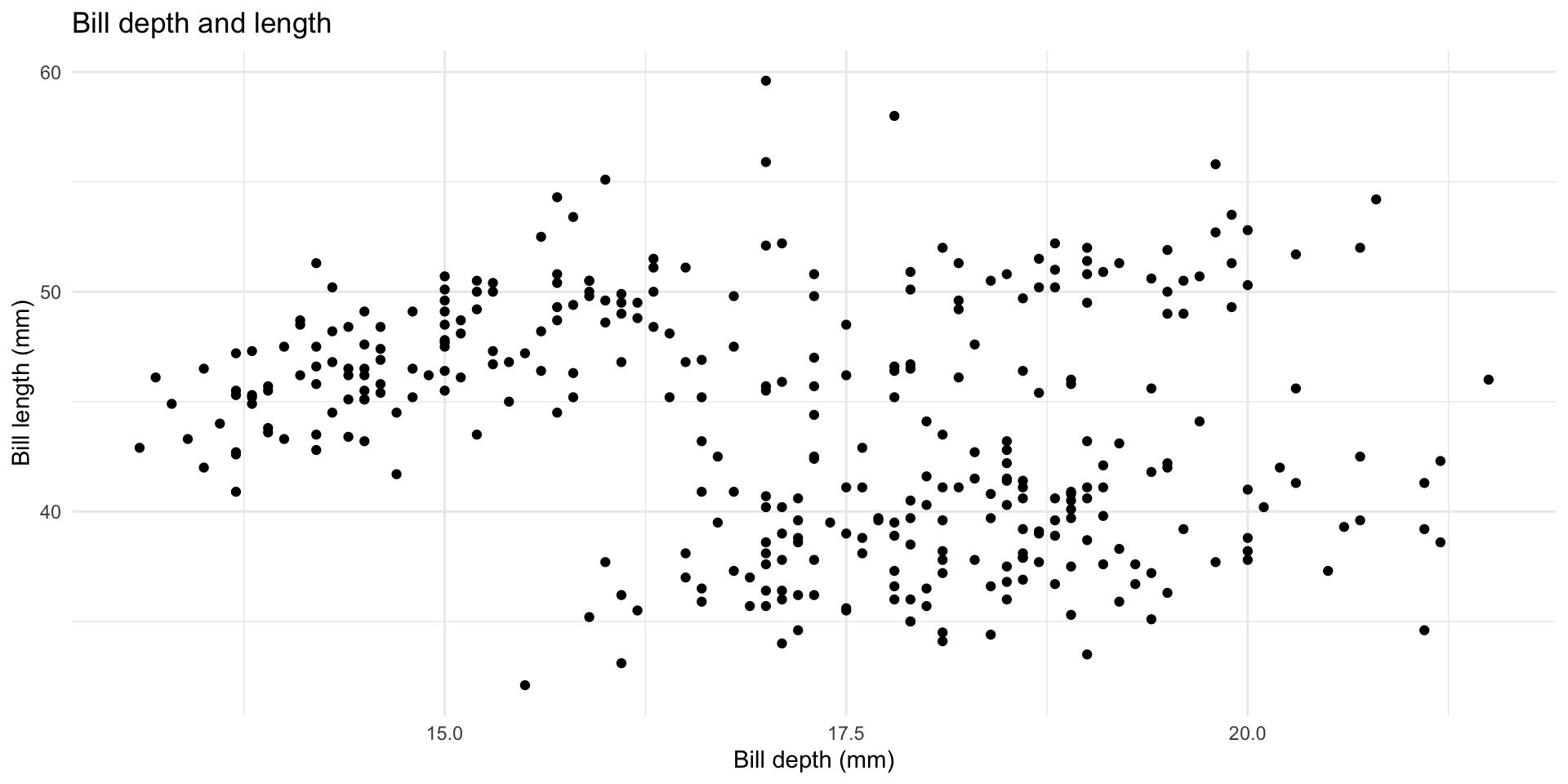
Simpson’s paradox
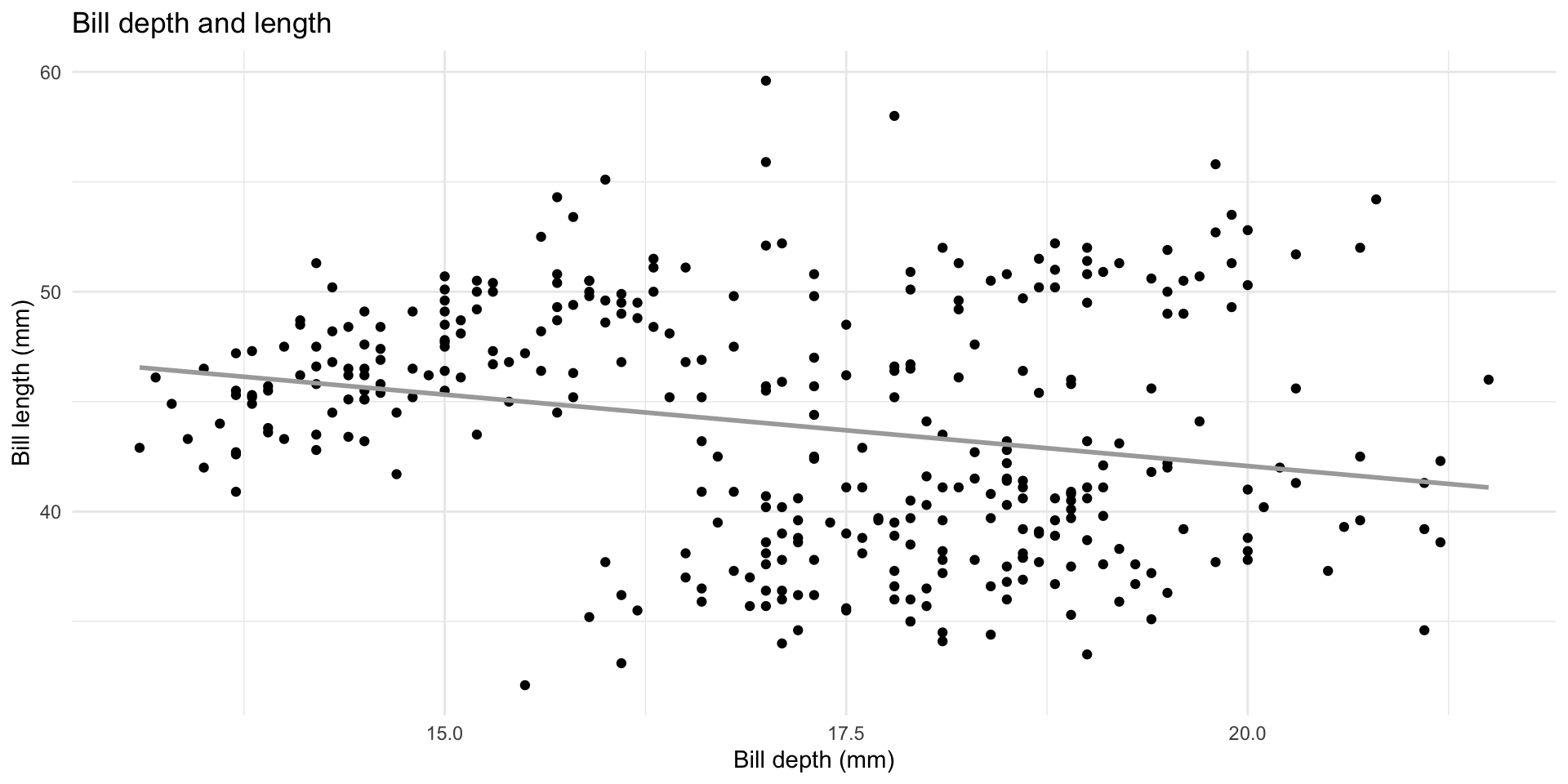
Simpson’s paradox
Simpson’s paradox
Supplemental Reading
Introduction to Modern Statistics Chap 4-6
Communicating with Data, Chap 3-4