1/18: Introduction to R and R Studio, working with data
1/25: Intro to Visualization
2/01: Probability, linear modeling
2/08: Data wrangling, model summaries
2/15: Simulation, Resampling 2/22: Iteration
3/01: Creating functions, debugging
3/15: Flex: more modeling (brms, glmmTMB)
3/29: Spatial data or tidymodeling
NB: We already know better ways to do this using summarize().
Common way to use loops
#define the elements to loop overspecies <-sort(unique(penguins$species))#define how many times to do the loopnspecies <-length(species)#create a place to store resultsmean_mass <-vector(length=nspecies)#get loopyfor (isp in1:nspecies) { species.data <- penguins[penguins$species==species[isp], ] mean_mass[isp] <-mean(species.data$body_mass_g, na.rm =TRUE)print(mean_mass[isp])cat("Running species ", isp,"\n")}
A lot of this code is book-keeping rather than the thing we want to do.
purrr
for loops are simple, but they require lots of code that is mostly book-keeping.
Attention is then on this rather than the action the code is doing.
Functional programming abstracts the book-keeping of the loop to keep attention on the code that matters.
Series of apply functions in base R. (apply, tapply, sapply, lapply)
These all have slightly differences about how they are used.
purrr package is the tidyverse solution to the apply functions.
The syntax for creating an anonymous function in R is quite verbose so purrr provides a convenient shortcut: a one-sided formula.
models <- penguins %>%split(.$species) %>%map(~lm(body_mass_g ~ flipper_length_mm, data = .))#The 1st ~ is shorthand for a function#The '.' shows where the stuff passed to map gets used.
models |>map(summary) |>#run 'summary() for each modelmap_dbl(~.$r.squared) # find the R-squared
Extracting named components is a common operation, so can use a string instead.
models |>map(summary) |>#run 'summary() for each modelmap_dbl("r.squared") #find the R-squared
Exercise 1
Write code that uses one of the map functions to:
Compute the mean of every numeric column in palmerpenguins::penguins.
Determine the type of each column in nycflights13::flights.
Compute the number of unique values in each column of palmerpenguins::penguins.
05:00
Extending to multiple input lists
map2 allows you to map over two sets of inputs.
map2(list1, list2, ~function(.x,.y), ...)
e.g. generate 3 sets of 5 normal random variables, with the means & standard deviations different in each set.
mu <-list(5, 10, -3)sigma <-list(1, 5, 10)map2(mu, sigma, rnorm, n =5) |>str()## List of 3## $ : num [1:5] 4.78 5.28 5.6 4.46 4.92## $ : num [1:5] 9.83 4.23 16.61 6.71 16.3## $ : num [1:5] 2.438 4.681 -3.453 -16.228 0.252
More than 2 inputs, use pmap
e.g. same problem as previous, but now n varies in each set.
n <-list(1, 3, 5)mu <-list(5, 10, -3)sigma <-list(1, 5, 10)args1 <-list(mean = mu, sd = sigma, n = n)args1 |>pmap(rnorm) |>str()## List of 3## $ : num 7.46## $ : num [1:3] 14.17 9.36 4.04## $ : num [1:5] -15.98 -15.89 -17.65 5.46 3.53
Safest to use named arguments with pmap, as it will do positional matching if not.
Debugging using safely
Handling errors can be tricky to diagnose with map.
It’s not as obvious when/where things break.
Can use safely(). e.g.
safe_log <-safely(log, otherwise =NA_real_) #safe_log return a NA if log() returns error, plus error msg. list("a", 10, 100) |>map(safe_log) |>#<<transpose() |>simplify_all()## $result## [1] NA 2.302585 4.605170## ## $error## $error[[1]]## <simpleError in .Primitive("log")(x, base): non-numeric argument to mathematical function>## ## $error[[2]]## NULL## ## $error[[3]]## NULL
Exercise 2
Create a data frame of samples from the palmerpenguins::penguins dataset, that contains 3 Adelies, 6 Gentoos, and 4 Chinstraps. (your new data frame will have 13 rows, with 3, 6, and 4 of the three species)(hint: use a nested dataframe, map2(), and slice_sample())
We have data from several years of crab surveys. The data for each year is contained in separate “.csv” files.
We would like to read these data into R, and combine them into a single data frame so we can inspect and plot them.
Write code to read these data into R, and combine them into a single dataframe.
b-d. Then produce 3 plots (of your choice) summarizing the full dataset. Include “b”, “c”, and “d” in the title of your plots.
For hints see next slide.
Hints for exercise 2:
you can use the following to get an object containing a list of files in a folder
::: {.cell}
data_path ="../data/crabs"# directory where the files are locatedfiles <-dir(path = data_path, pattern ="*.csv",full.names =TRUE) # names of files ending in ".csv"files## [1] "../data/crabs/CRABS_2001.csv" "../data/crabs/CRABS_2002.csv"## [3] "../data/crabs/CRABS_2003.csv" "../data/crabs/CRABS_2004.csv"## [5] "../data/crabs/CRABS_2005.csv" "../data/crabs/CRABS_2006.csv"## [7] "../data/crabs/CRABS_2007.csv" "../data/crabs/CRABS_2008.csv"## [9] "../data/crabs/CRABS_2009.csv" "../data/crabs/CRABS_2010.csv"## [11] "../data/crabs/CRABS_2011.csv" "../data/crabs/CRABS_2012.csv"## [13] "../data/crabs/CRABS_2013.csv" "../data/crabs/CRABS_2014.csv"## [15] "../data/crabs/CRABS_2015.csv" "../data/crabs/CRABS_2016.csv"## [17] "../data/crabs/CRABS_2017.csv" "../data/crabs/CRABS_2018.csv"## [19] "../data/crabs/CRABS_2019.csv"
::: - look at the help for ‘dir’ for additional functionality
Steller sea lion pups revisited
We have data on Steller sea lion pup counts over time at a bunch of rookeries in Alaska.
The number of data points for each rookery is not the same.
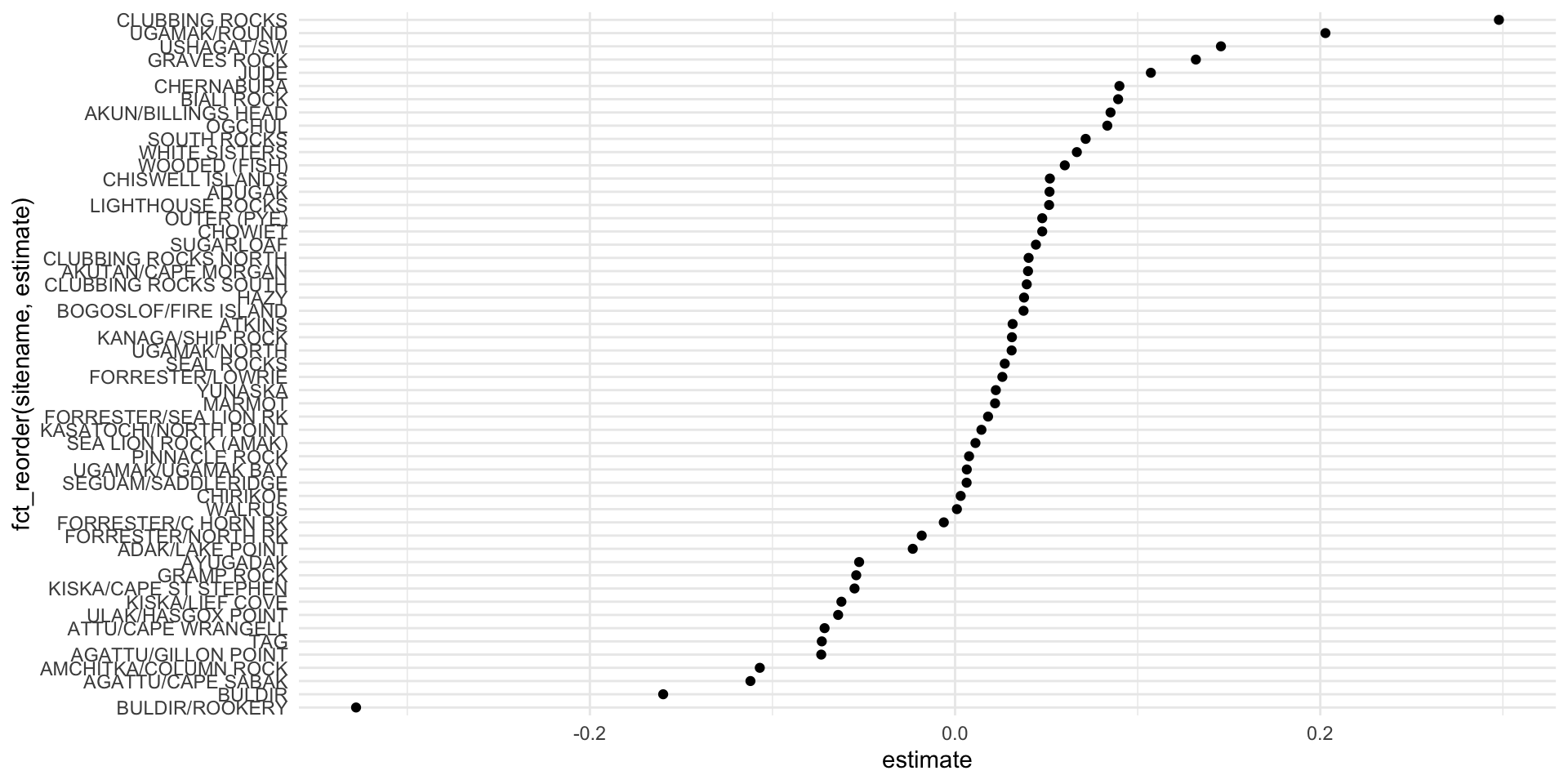
We want to investigate the annual trend in counts for each rookery.
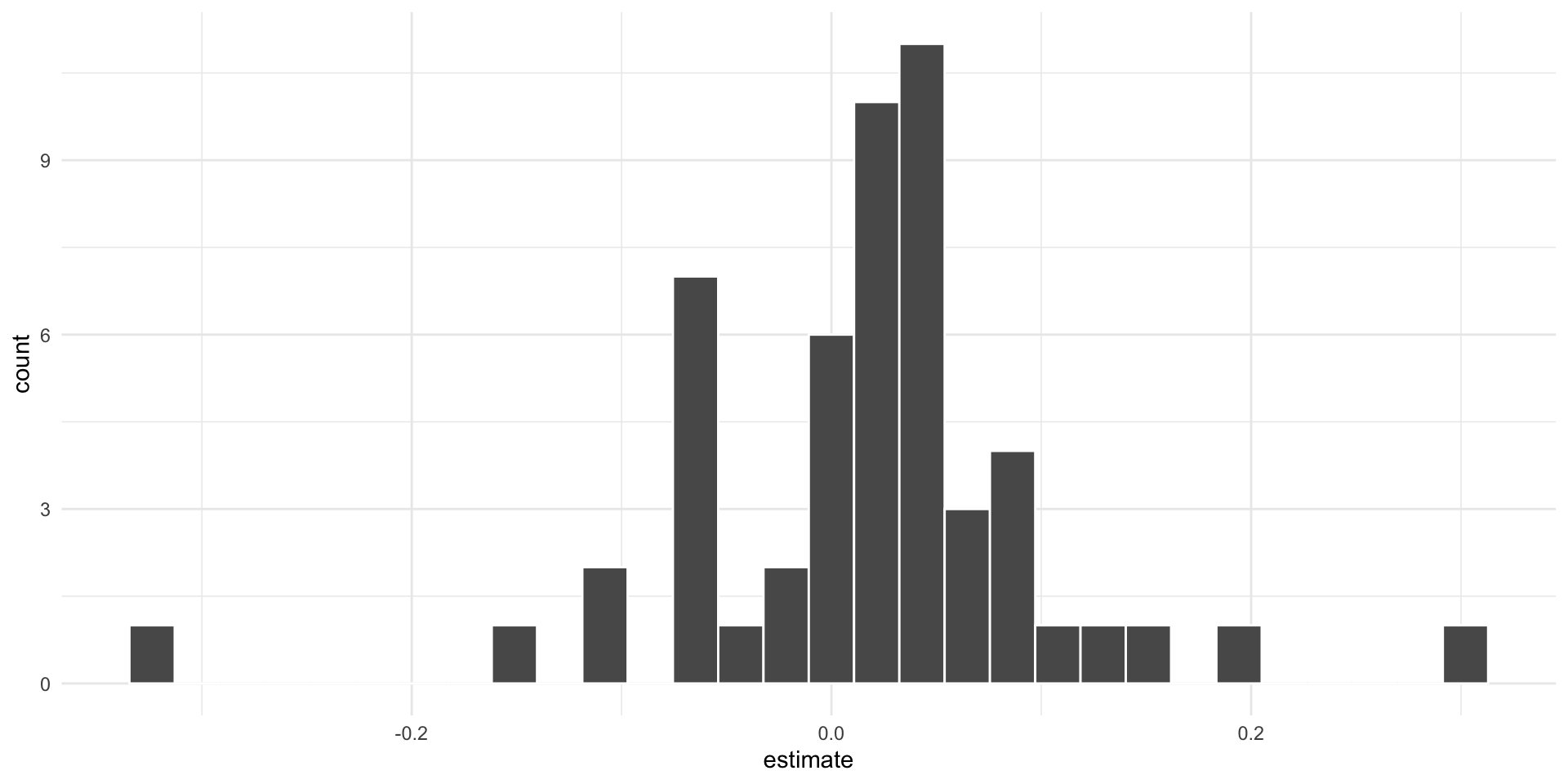
We want to plot the slopes of the regressions using a histogram.
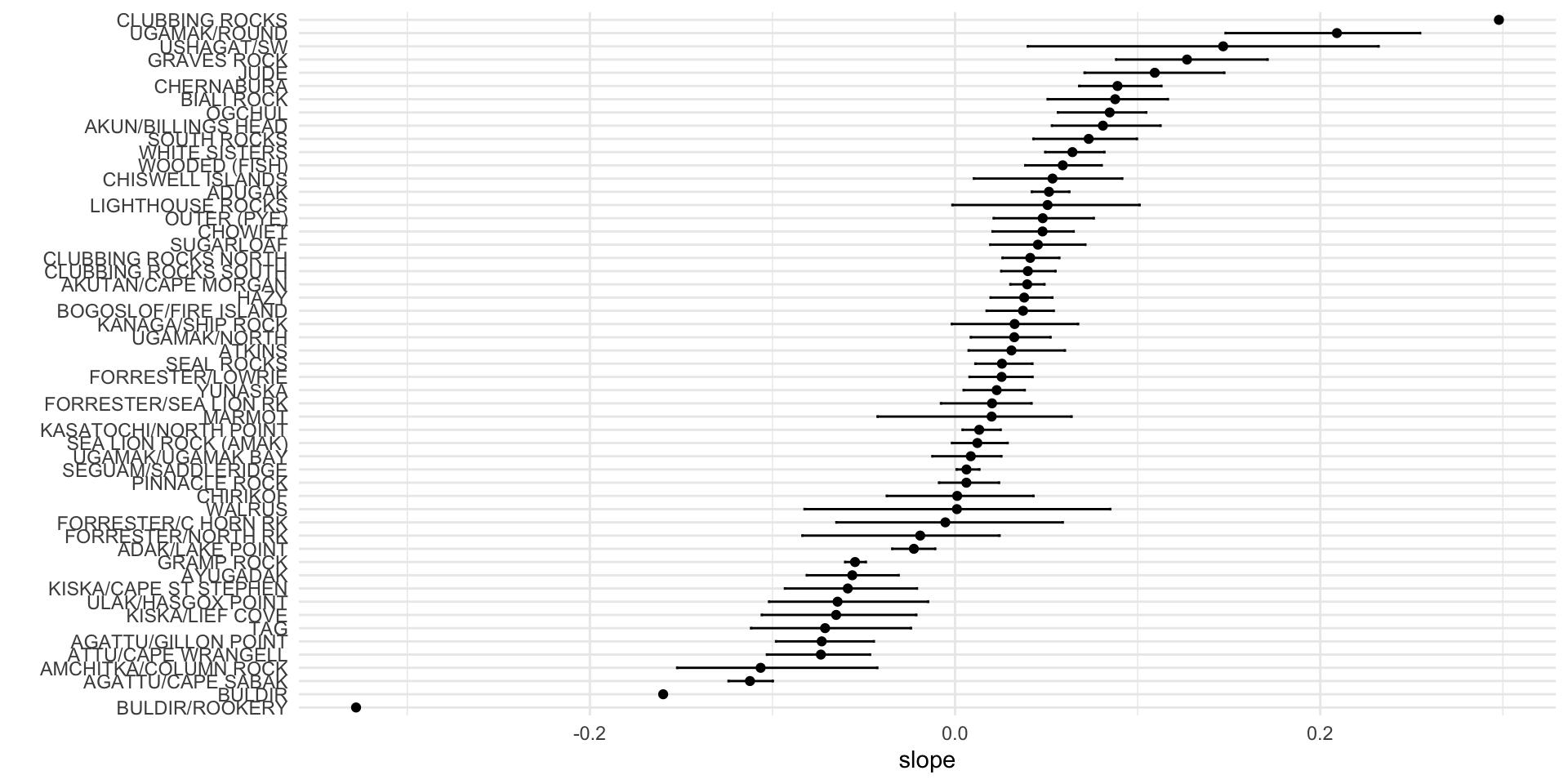
We want to obtain confidence intervals of the slope estimates using bootstrapping.
ssl <-read_csv("../data/SSLpupcounts.csv")slice(ssl,1:3)## # A tibble: 3 × 43## sitename `1961` `1965` `1967` `1968` `1971` `1973` `1975` `1976` `1978` `1979`## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>## 1 ADAK/LA… NA NA NA NA NA NA NA NA NA 20## 2 ADUGAK NA NA NA NA NA NA NA NA NA NA## 3 AGATTU NA NA NA NA NA NA NA NA NA 183## # … with 32 more variables: `1981` <dbl>, `1982` <dbl>, `1984` <dbl>,## # `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>, `1989` <dbl>,## # `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>, `1994` <dbl>,## # `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>, `2000` <dbl>,## # `2001` <dbl>, `2002` <dbl>, `2003` <dbl>, `2004` <dbl>, `2005` <dbl>,## # `2007` <dbl>, `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>,## # `2012` <dbl>, `2013` <dbl>, `2014` <dbl>, `2015` <dbl>ssl_long <- ssl |>pivot_longer(names_to ="year",values_to ="count",-sitename) |>drop_na() |>mutate(year =as.numeric(year)) |>filter(year >=2000, count >0) |>mutate(log_count =log(count),year2 = year-2000) |>I()
# we'll do resampling from the residuals for each year within each rookery# rather than getting complicated with nested lists, we'll use sample_frac() to do the resamplestosample <- ssl_boot |>select(sitename, resid) |>group_by(sitename)resamples <-map_dfr(seq_len(nboot), ~slice_sample(tosample, prop =1, replace =TRUE)) |>ungroup() |>mutate(replicate =rep(1:nboot, each =nrow(tosample)))resamples## # A tibble: 37,200 × 3## sitename resid replicate## <chr> <dbl> <int>## 1 ADAK/LAKE POINT 0.0454 1## 2 ADAK/LAKE POINT 0.0509 1## 3 ADAK/LAKE POINT 0.0509 1## 4 ADAK/LAKE POINT 0.0886 1## 5 ADAK/LAKE POINT 0.0454 1## 6 ADAK/LAKE POINT 0.0509 1## 7 ADAK/LAKE POINT -0.0985 1## 8 ADUGAK -0.0384 1## 9 ADUGAK -0.0193 1## 10 ADUGAK -0.0778 1## # … with 37,190 more rows
resamples contains our bootstraps. Let’s append them to the data frame so we can compute the new data and re-fit the models for each case.
ssl_bootmod <-map_dfr(seq_len(nboot), ~I(ssl_boot)) |>select(-resid, -sitename) |>bind_cols(resamples) |>mutate(log_count = fitted + resid) |>group_by(sitename, replicate) |>nest() # now have a data frame with a row for each site & replicatessl_bootmod## # A tibble: 5,300 × 3## # Groups: sitename, replicate [5,300]## sitename replicate data ## <chr> <int> <list> ## 1 ADAK/LAKE POINT 1 <tibble [7 × 8]> ## 2 ADUGAK 1 <tibble [8 × 8]> ## 3 AGATTU/CAPE SABAK 1 <tibble [10 × 8]>## 4 AGATTU/GILLON POINT 1 <tibble [8 × 8]> ## 5 AKUN/BILLINGS HEAD 1 <tibble [7 × 8]> ## 6 AKUTAN/CAPE MORGAN 1 <tibble [8 × 8]> ## 7 AMCHITKA/COLUMN ROCK 1 <tibble [5 × 8]> ## 8 ATKINS 1 <tibble [9 × 8]> ## 9 ATTU/CAPE WRANGELL 1 <tibble [8 × 8]> ## 10 AYUGADAK 1 <tibble [7 × 8]> ## # … with 5,290 more rows
We sometimes like to use the output of one iteration as input to the next. e.g. model population dynamics over time, iterated function is annual population update.
accumulate(letters[1:10], paste, sep =" + ")## [1] "a" ## [2] "a + b" ## [3] "a + b + c" ## [4] "a + b + c + d" ## [5] "a + b + c + d + e" ## [6] "a + b + c + d + e + f" ## [7] "a + b + c + d + e + f + g" ## [8] "a + b + c + d + e + f + g + h" ## [9] "a + b + c + d + e + f + g + h + i" ## [10] "a + b + c + d + e + f + g + h + i + j"
Population projections
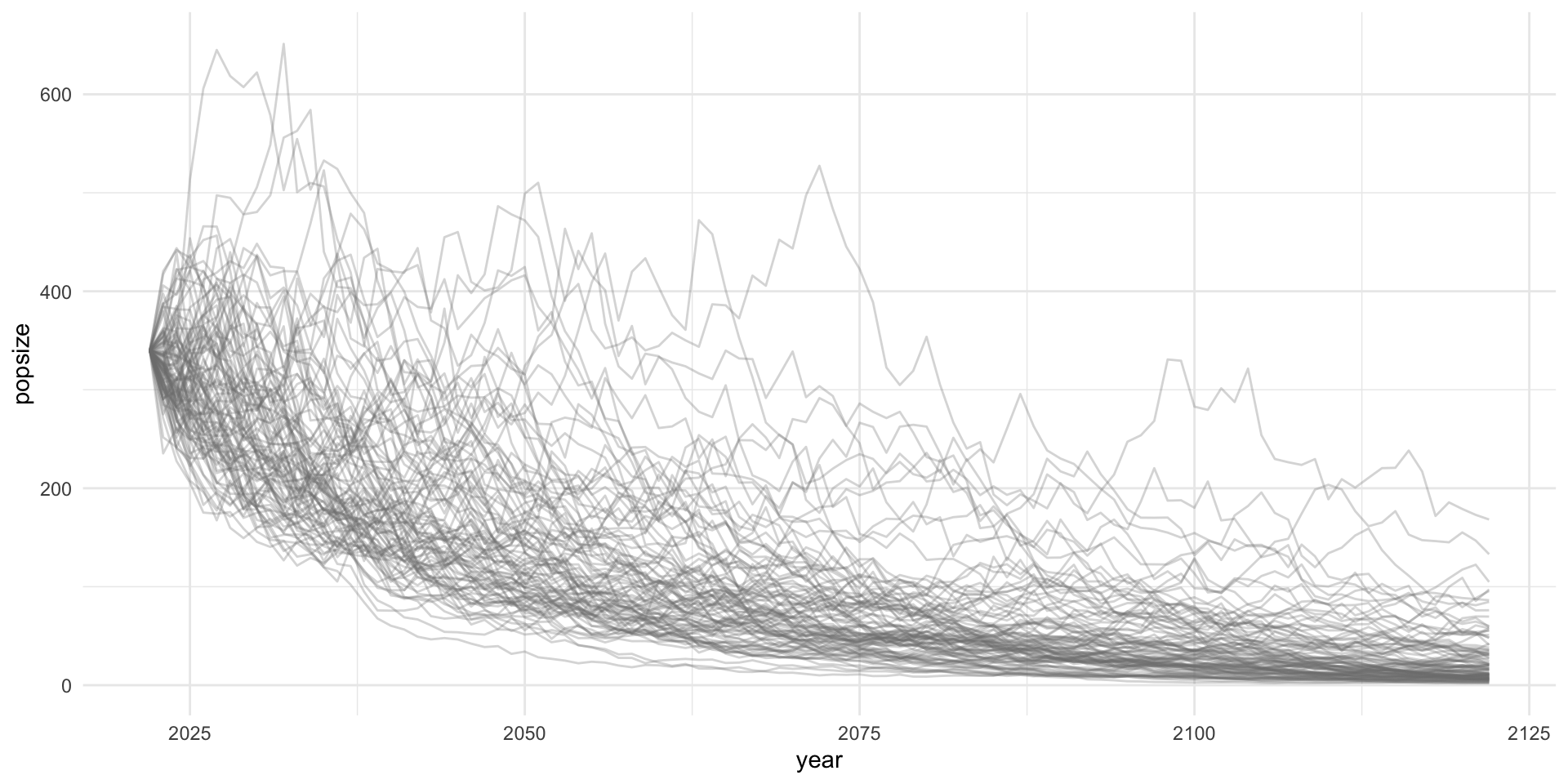
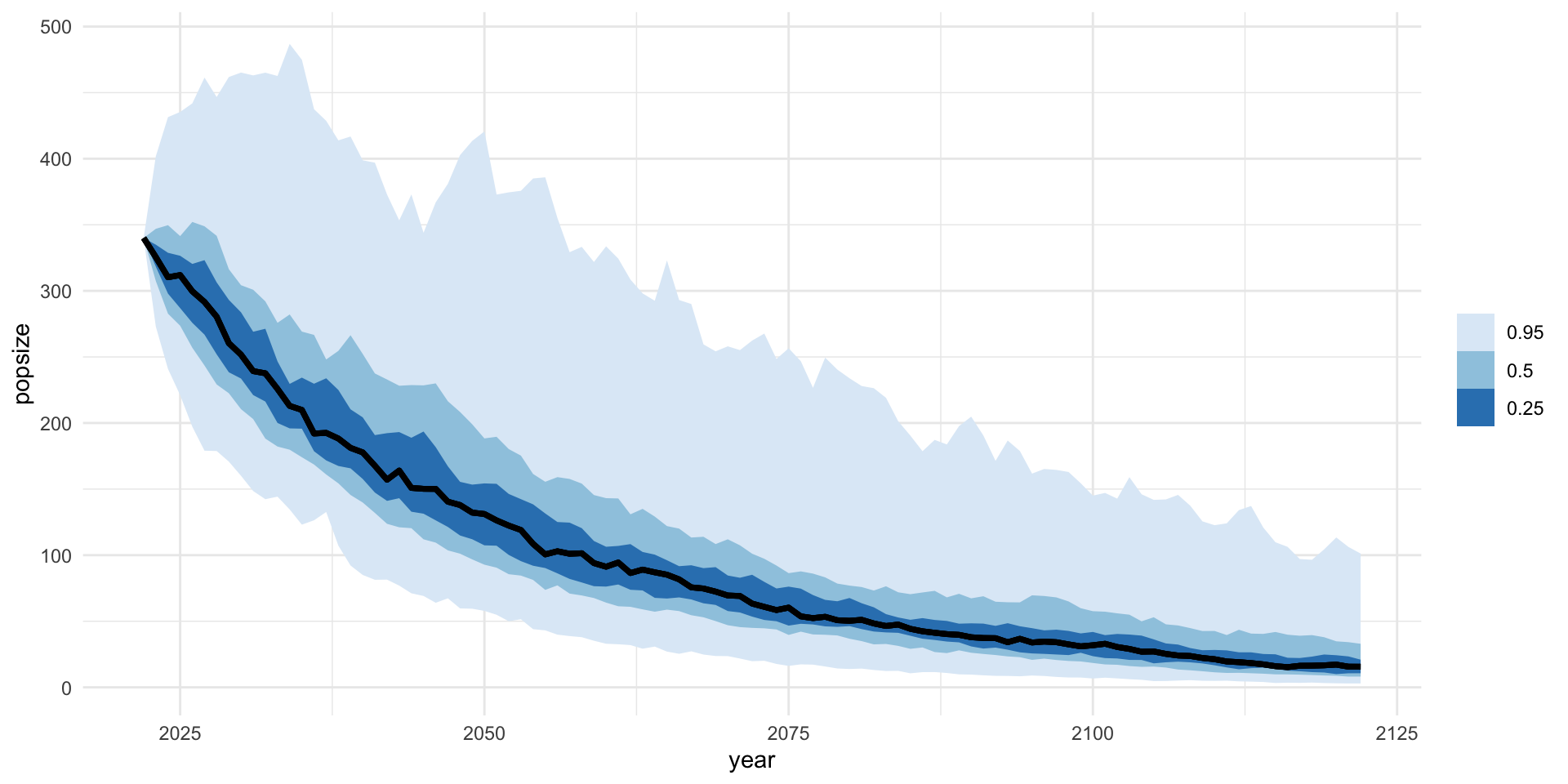
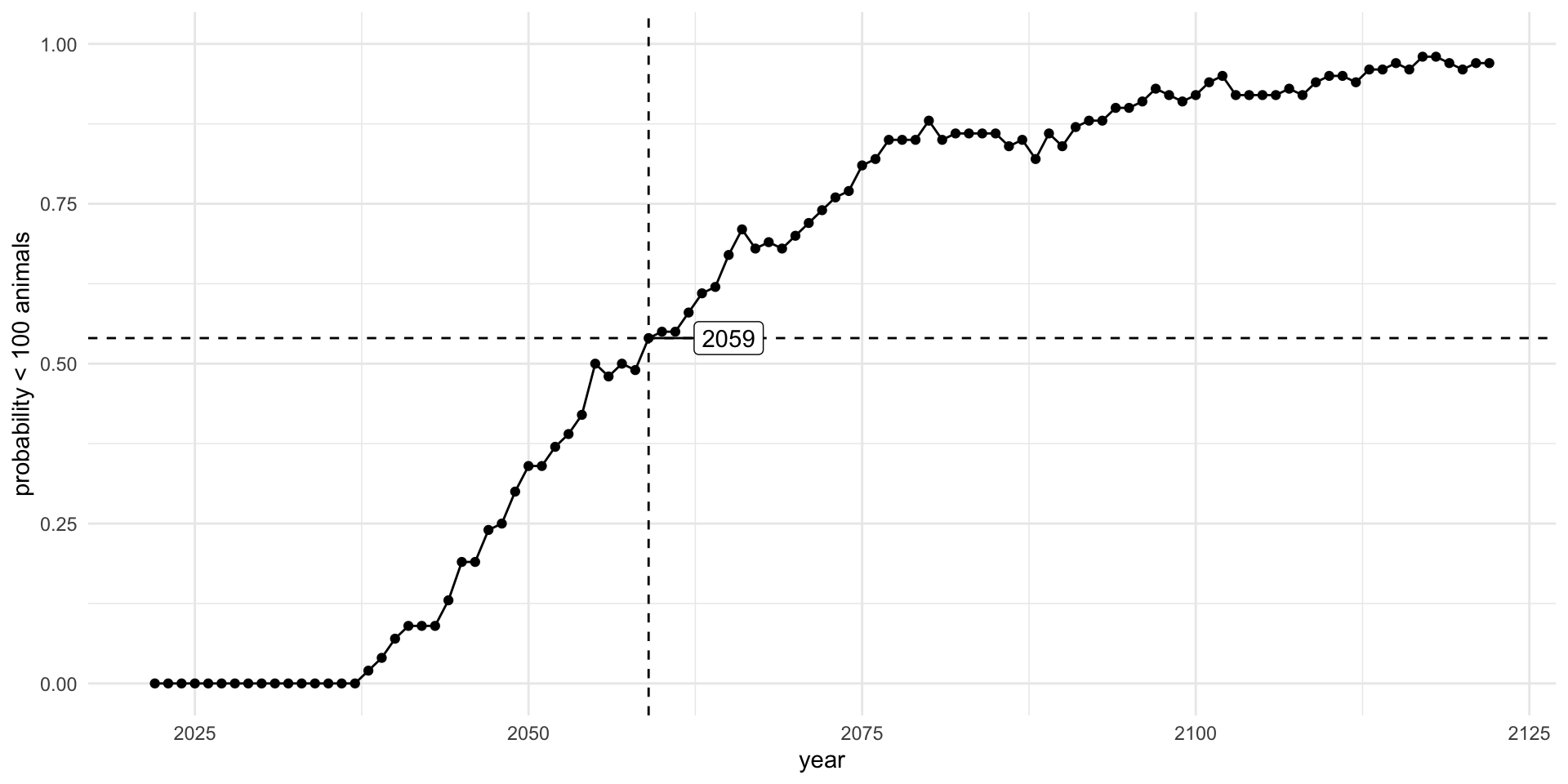
Status for endangered species are often based on a risk evaluation of population projections. We want to project population dynamics forward in time given uncertainty in future dynamics. We want to do this lots of times to quantify the risk of extinction.
Current (2022) estimates of the North Atlantic Right Whale population are 340 individuals. The population has been declining on average around 3% per year since 2011. What is the year in which the probability that the right whale population drops below 100 individuals is at least 50% (P(N<100)>=0.5)?
nsim <-100nyr <-100initN <-340sd_proc <-0.1lambda <-0.97growth_rates <-map(seq_len(nsim), ~rlnorm(nyr,log(lambda),sd_proc))# population modelpop_update <-function(N, growth_rate =1) N*growth_rate# population projection for each time series of process errorspop_proj <-tibble(sim =seq_len(nsim)) |>mutate(popsize =map(growth_rates,~accumulate(., pop_update, .init = initN))) |>unnest(cols =c(popsize)) |>mutate(year =rep(2022:2122, nsim))pop_proj## # A tibble: 10,100 × 3## sim popsize year## <int> <dbl> <int>## 1 1 340 2022## 2 1 300. 2023## 3 1 294. 2024## 4 1 360. 2025## 5 1 376. 2026## 6 1 386. 2027## 7 1 309. 2028## 8 1 298. 2029## 9 1 230. 2030## 10 1 202. 2031## # … with 10,090 more rows
avoidg loops over the data-intensive dimension in an object altogether.
the latter can be achieved by performing mainly vector-to-vecor or matrix-to-matrix computations (often > 100x faster than for() or apply() or map()).
Make use of existing speed-optimized R functions (e.g.: rowSums, rowMeans, table) or write your own fast functions.
xdat <-matrix(rnorm(1000000), 100000, 10)system.time(x_mean <-apply(xdat, 1, mean)) user system elapsed 1.2140.0294.087system.time(x_mean <-rowMeans(xdat)) user system elapsed 0.0050.0010.013
Lab Exercise 3/3
data/eukaryotes.tsv contains a NCBI Eukaryotic genome dataset, with basic information about the genomic content of all eukaryotes that were uploaded to the NCBI Genome database.
It contains accession numbers, information about the quality of the genome and stats such a average genome size and GC-content.
Use glimpse() and other data exploration to get familiar with the data. Then use map_* functions to answer the following:
How many different organisms are there in the dataset?
How many different institutes (centers) submitted a genome?
The data seem to be grouped in groups. How many groups are there?
How many sub groups are there?
How many different organisms are there per group?
How many different institutes (centers) submitted a genome per group?
How many sub groups are there per group?
Lab Exercise 3 continued…
We might hypothesisze that “The bigger the size of a genome, the higher the number of proteins”.
Fit a linear model of log10_proteins ~ log10_size_mb for each group.
Extract the R^2 for each model and print these for each group.
Assess the validity of your modeling approach.
Obtain and plot predictions for each group for genome sizes 0.5, 123, and 500 MB.
How do you interpret the results in terms of the original hypothesis?
BONUS use residual bootstrapping to obtain distributions for the predictions made in part 11.