hills$climb ##print a vector
[1] 650 2500 900 800 3070 2866 7500 800 800 650 2100 2000 2200 500 1500
[16] 3000 2200 350 1000 600 300 1500 2200 900 600 2000 800 950 1750 500
[31] 4400 600 5200 850 5000
select(hills, climb)
climb
Greenmantle 650
Carnethy 2500
Craig Dunain 900
Ben Rha 800
Ben Lomond 3070
Goatfell 2866
Bens of Jura 7500
Cairnpapple 800
Scolty 800
Traprain 650
Lairig Ghru 2100
Dollar 2000
Lomonds 2200
Cairn Table 500
Eildon Two 1500
Cairngorm 3000
Seven Hills 2200
Knock Hill 350
Black Hill 1000
Creag Beag 600
Kildcon Hill 300
Meall Ant-Suidhe 1500
Half Ben Nevis 2200
Cow Hill 900
N Berwick Law 600
Creag Dubh 2000
Burnswark 800
Largo Law 950
Criffel 1750
Acmony 500
Ben Nevis 4400
Knockfarrel 600
Two Breweries 5200
Cockleroi 850
Moffat Chase 5000MAR 536: Lab 2
Dr. Gavin Fay
01/25/2023
Plots are like onions…they have layers
Both base R and ggplot use a layers approach to plotting.
- Plot type
- Points
- Lines
- Colors
- Labels
- Styles
- etc.

ggplot2 \(\in\) tidyverse

- ggplot2 is tidyverse’s data visualization package
ggin “ggplot2” stands for Grammar of Graphics- Inspired by the book Grammar of Graphics by Leland Wilkinson
Grammar of Graphics
A grammar of graphics is a tool that enables us to concisely describe the components of a graphic

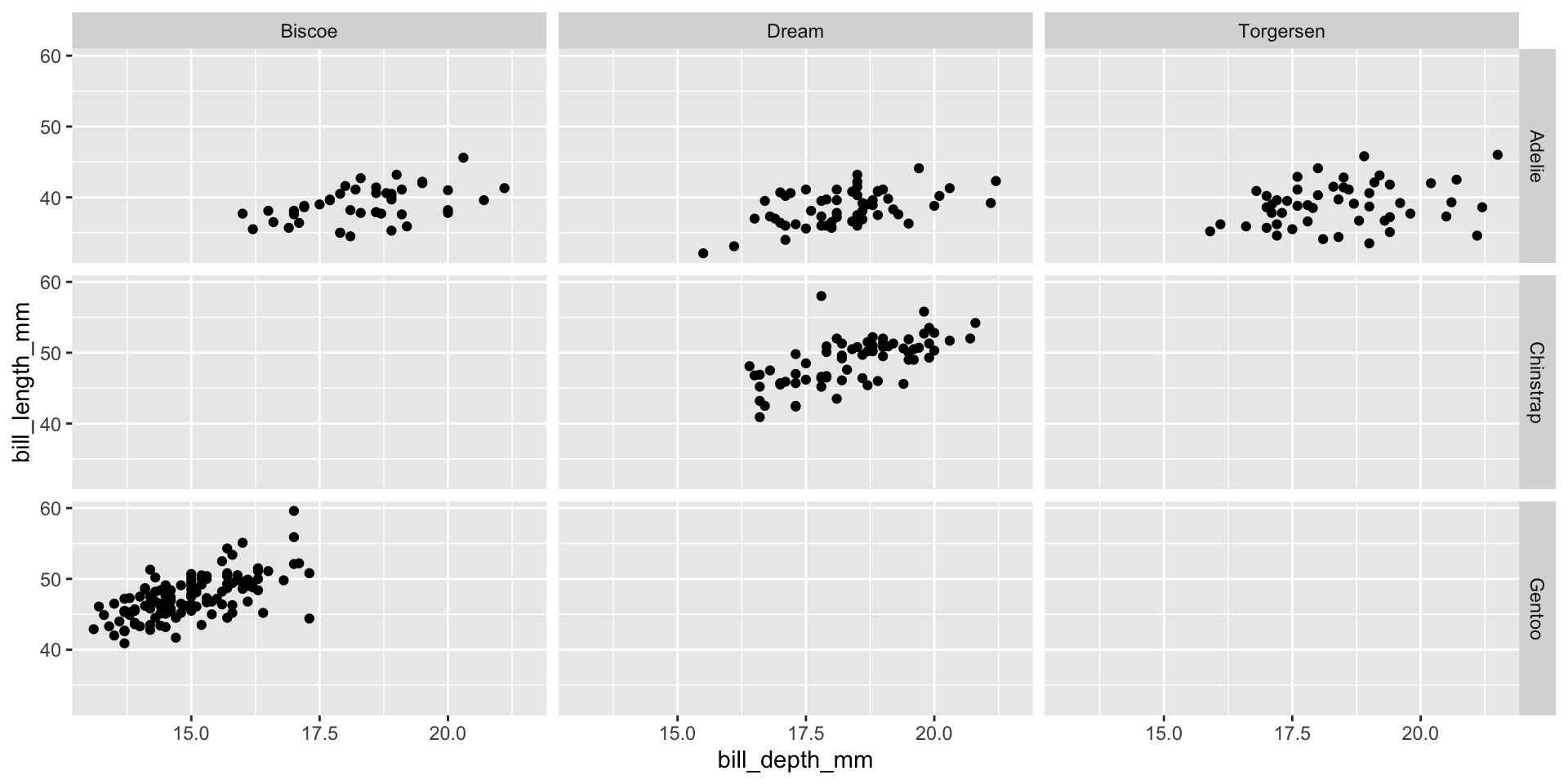
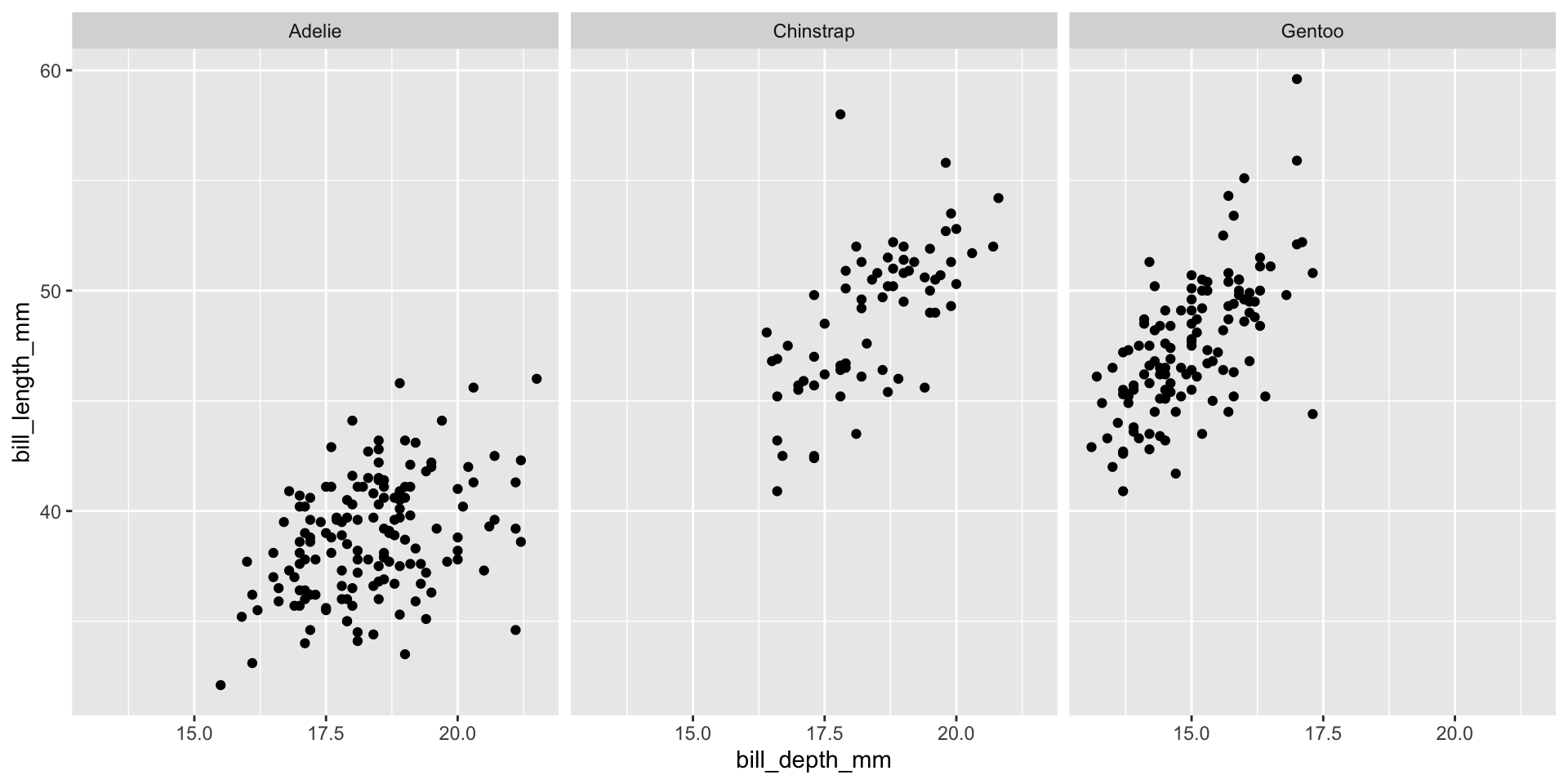
Palmer Penguins
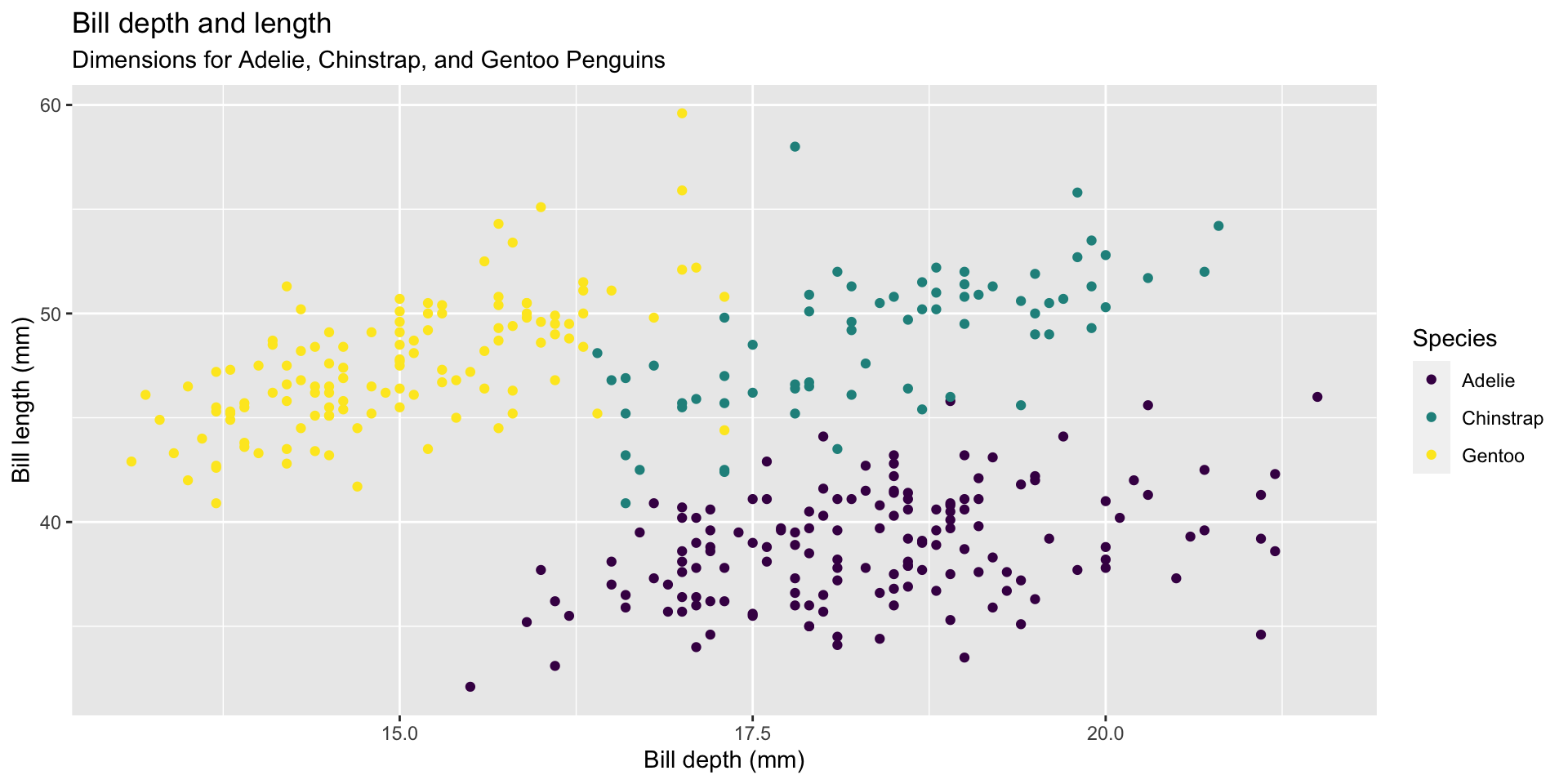
ggplot(data = penguins,
mapping = aes(x = bill_depth_mm, y = bill_length_mm,
colour = species)) +
geom_point() +
labs(title = "Bill depth and length",
subtitle = "Dimensions for Adelie, Chinstrap, and Gentoo Penguins",
x = "Bill depth (mm)", y = "Bill length (mm)",
colour = "Species") +
scale_color_viridis_d()By default R uses variable names as axis labels. Use labs() to add text & captions, etc.
Lab exercise 2/3
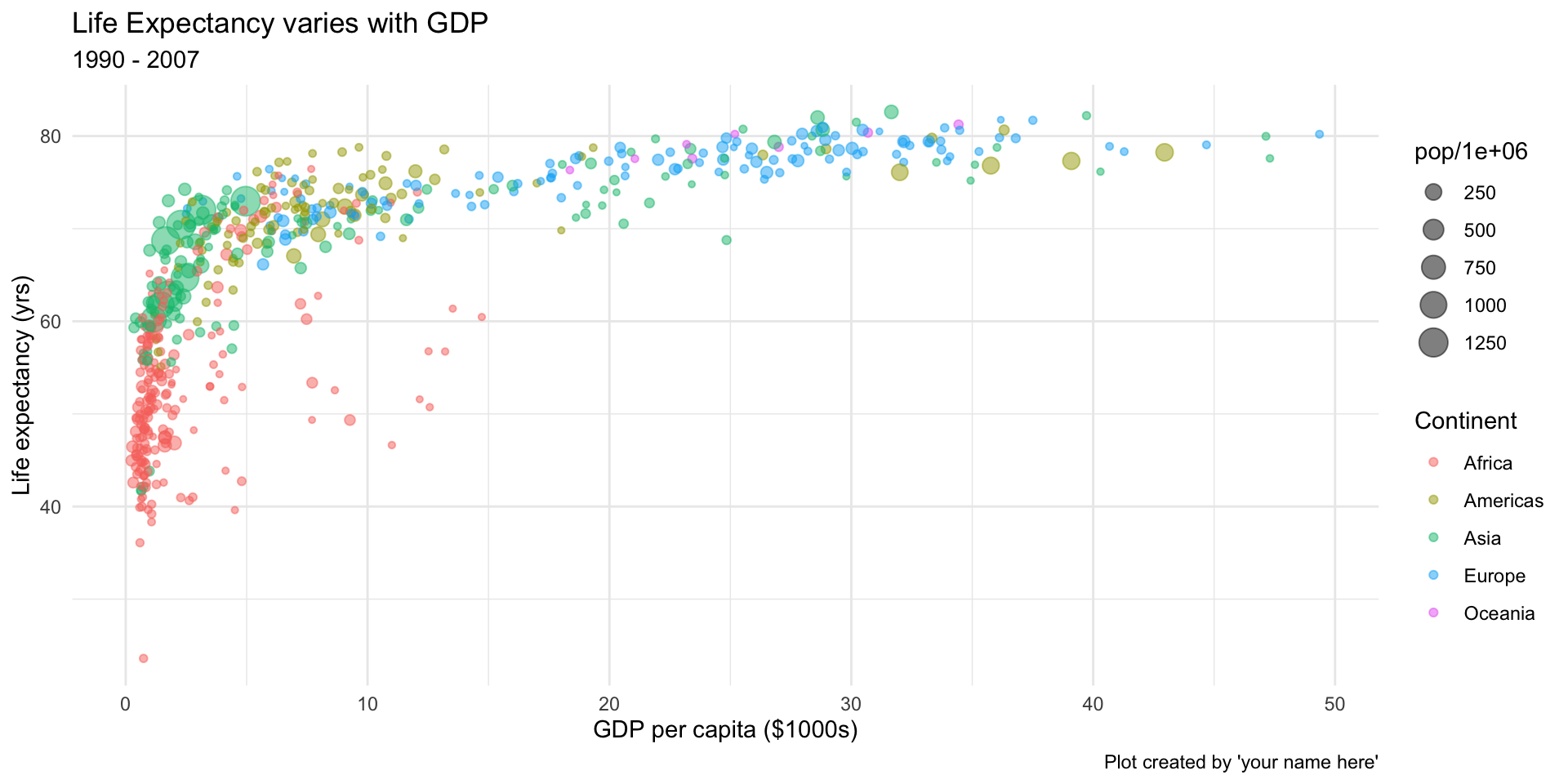
- Use the
gapminderdata to replicate as close as possible this graph. (Try out different ‘themes’ with+ theme_XXXX())
- bonus plot time series of life expectancy by continent and country. (You can use
geom_line()to link points)
Data: Lending Club
Thousands of loans made through the Lending Club, which is a platform that allows individuals to lend to other individuals
Not all loans are created equal – ease of getting a loan depends on (apparent) ability to pay back the loan
Data includes loans made, these are not loan applications

Histograms
geom_histogram()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.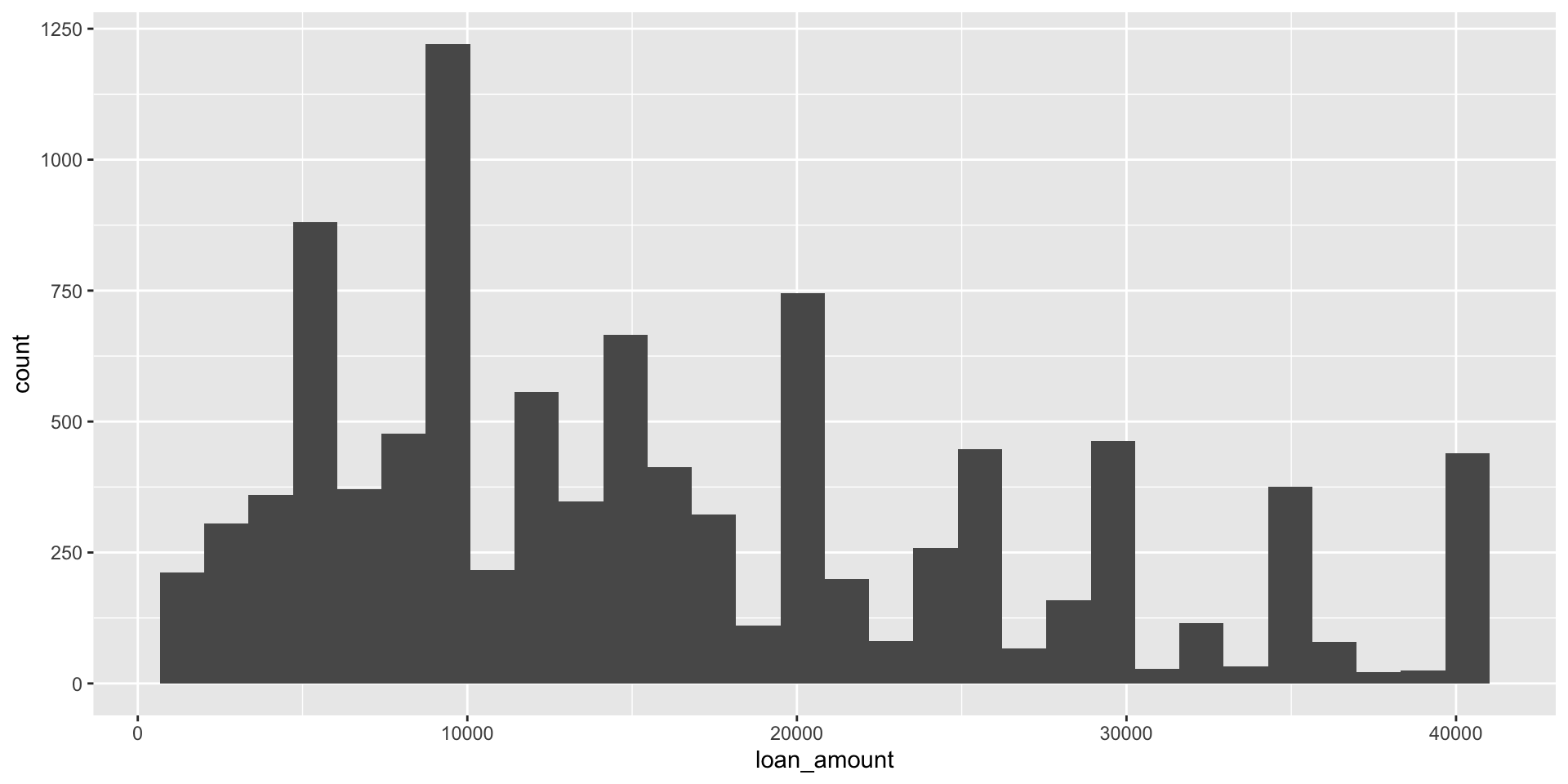
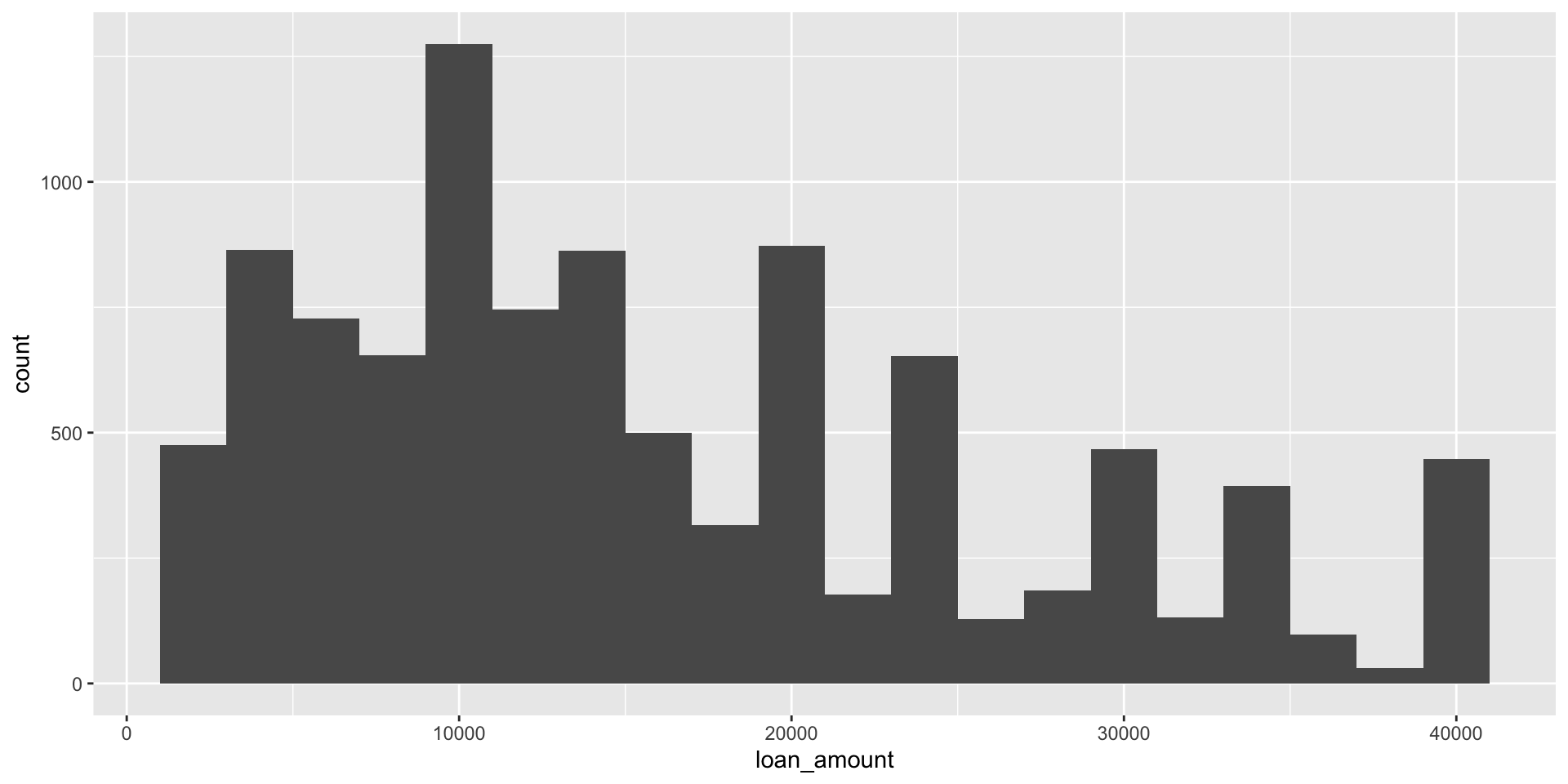
Histograms and binwidth
binwidth = 2000
Customizing histograms
Fill with a categorical variable
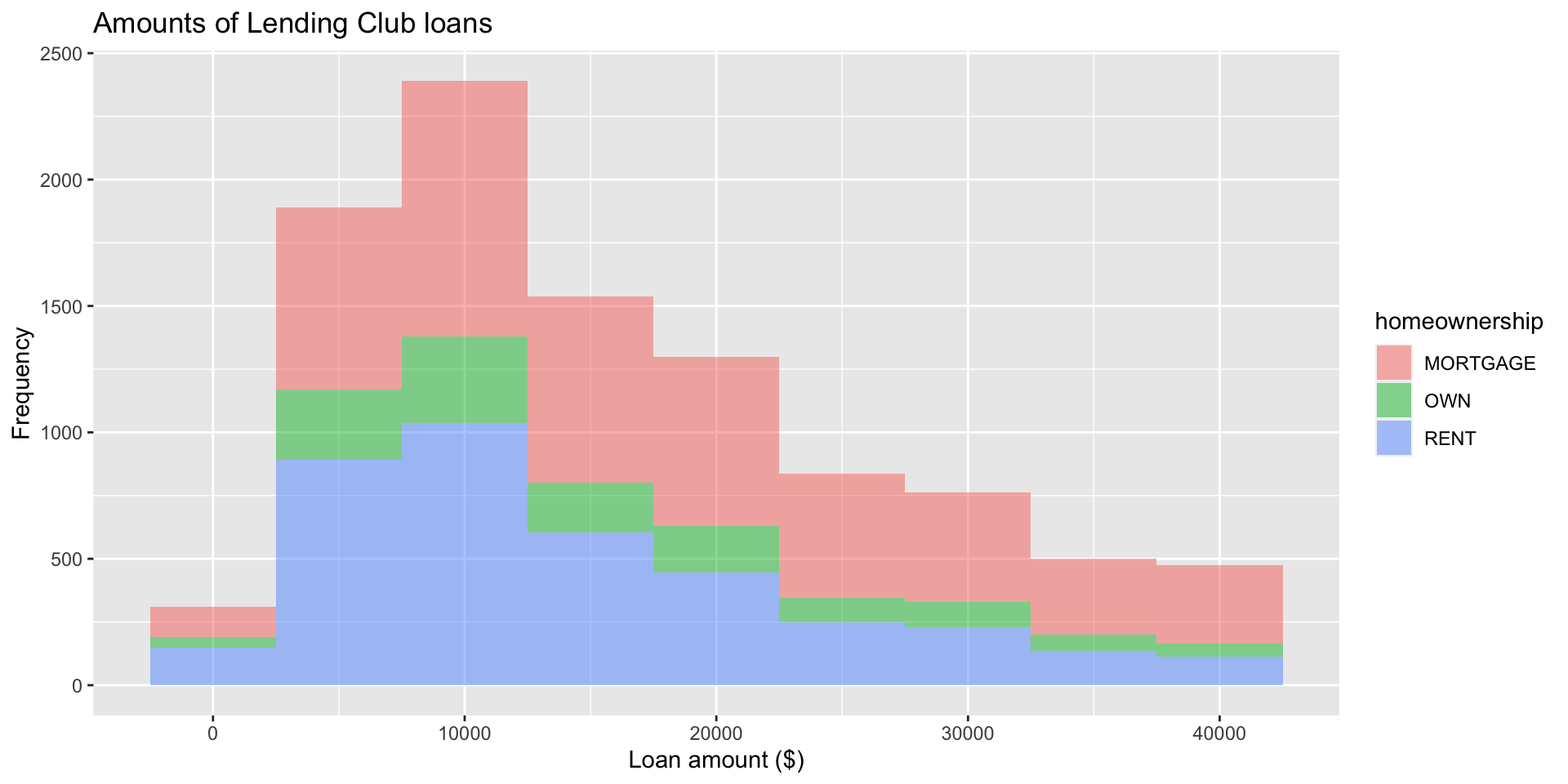
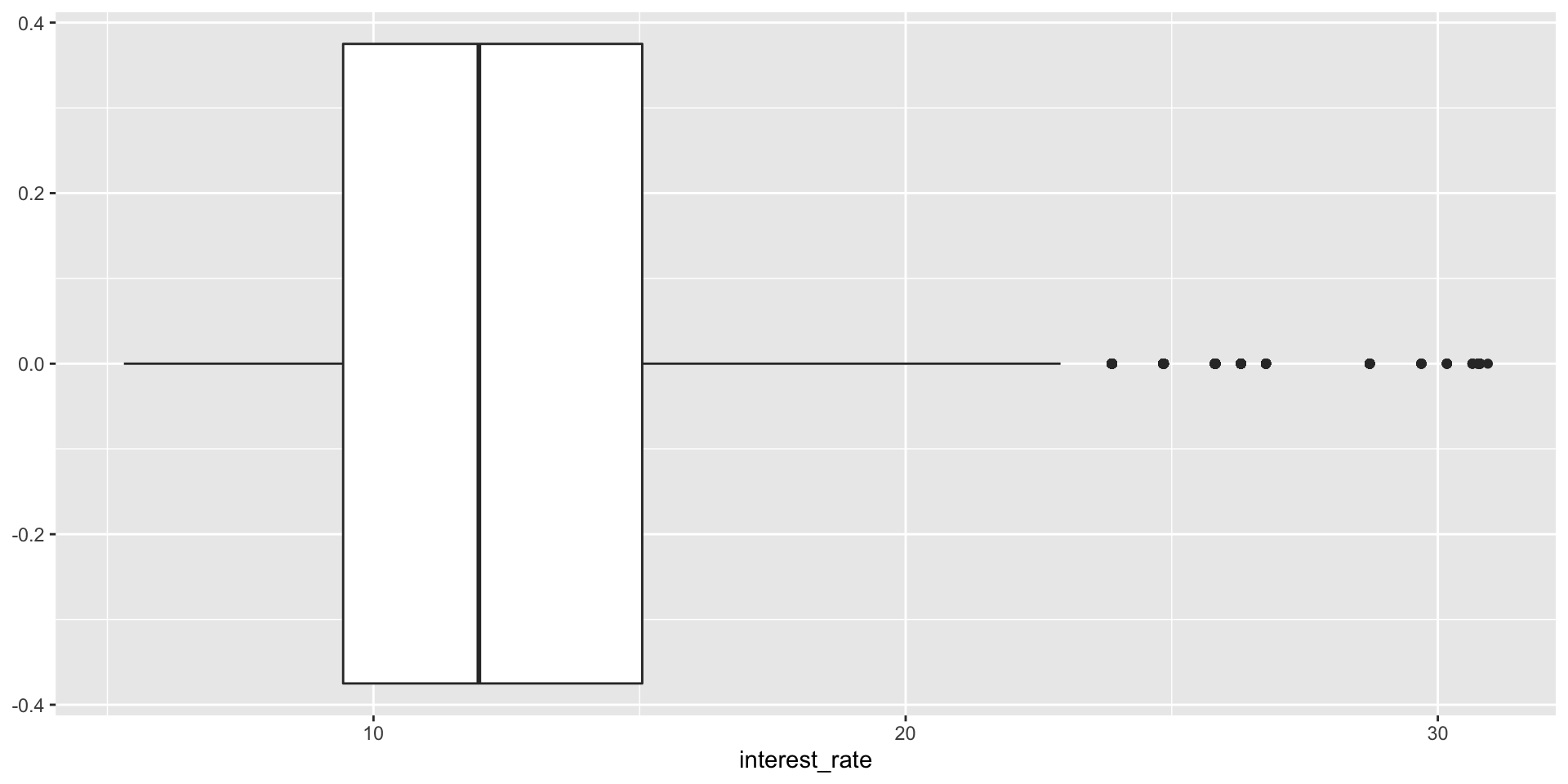
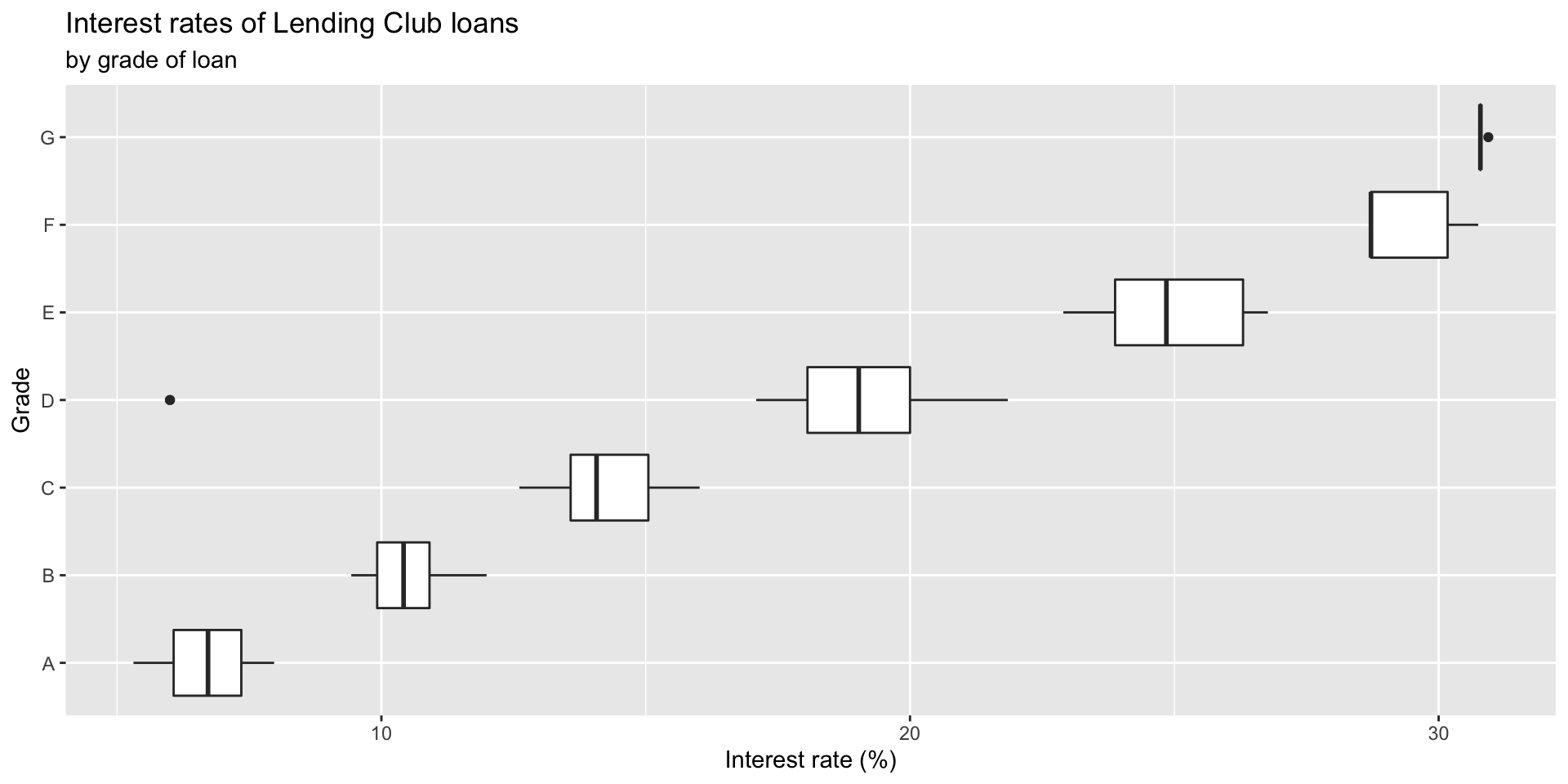
Box plots
Use geom_boxplot().
Adding a categorical variable
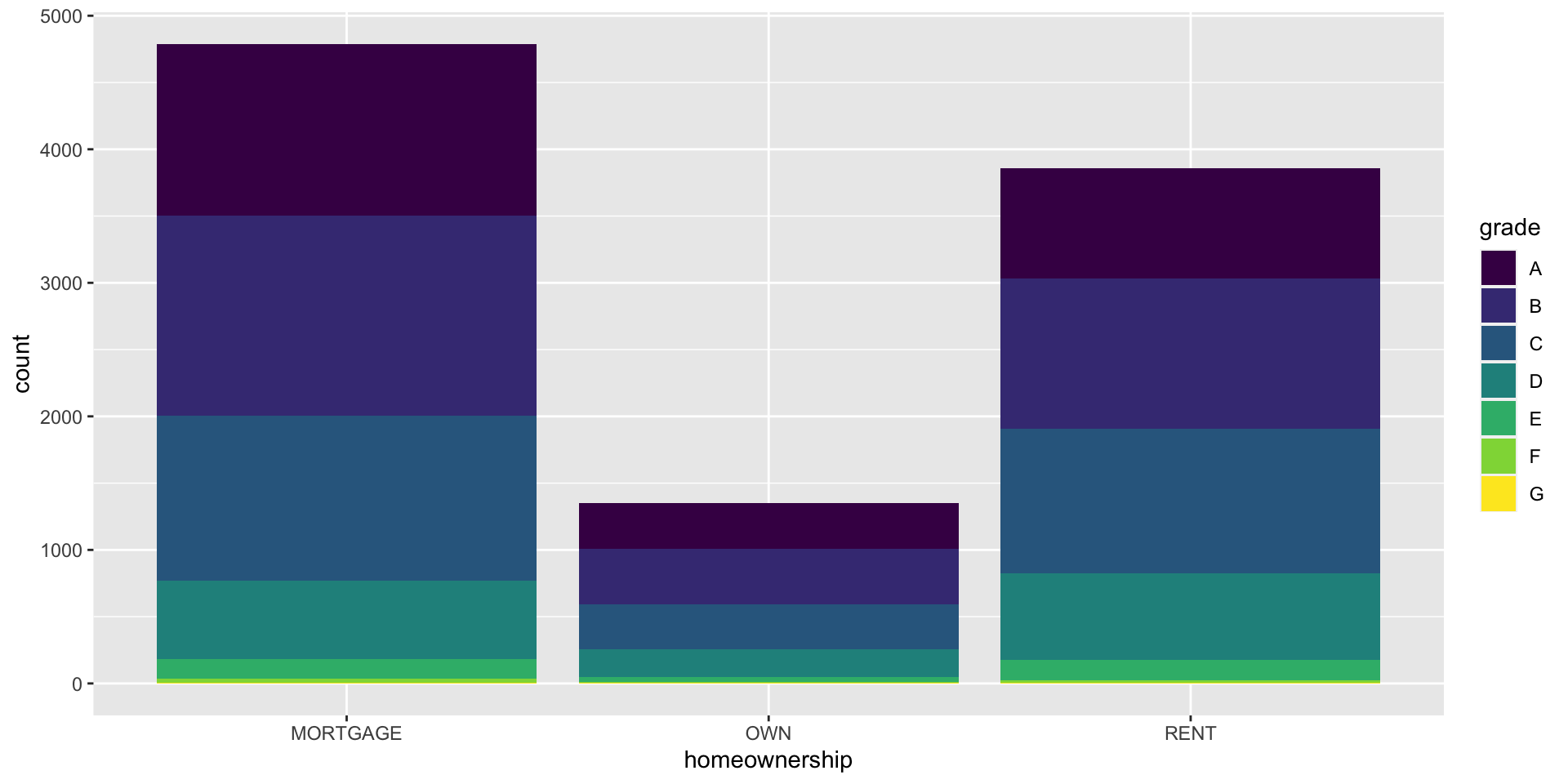
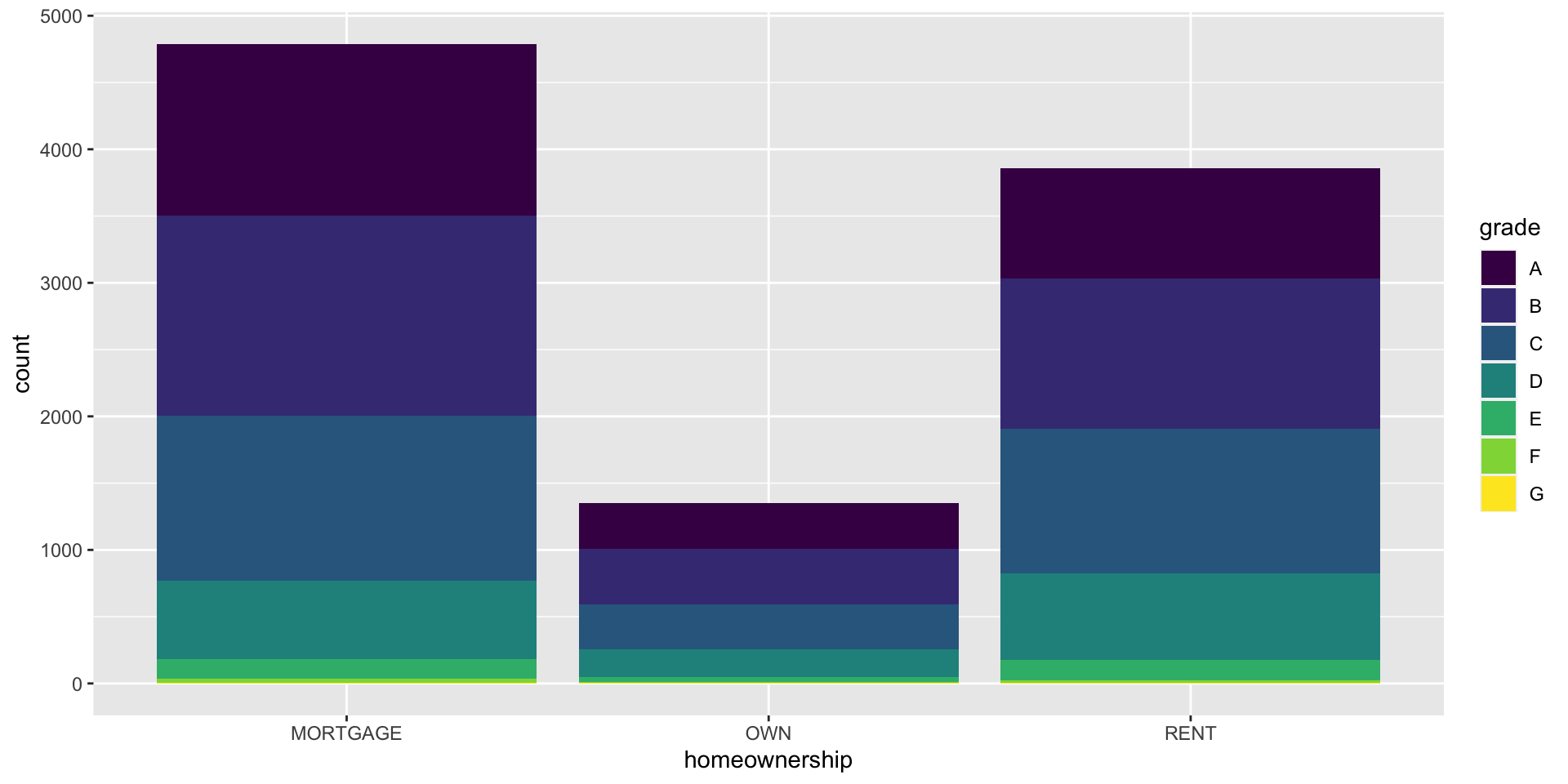
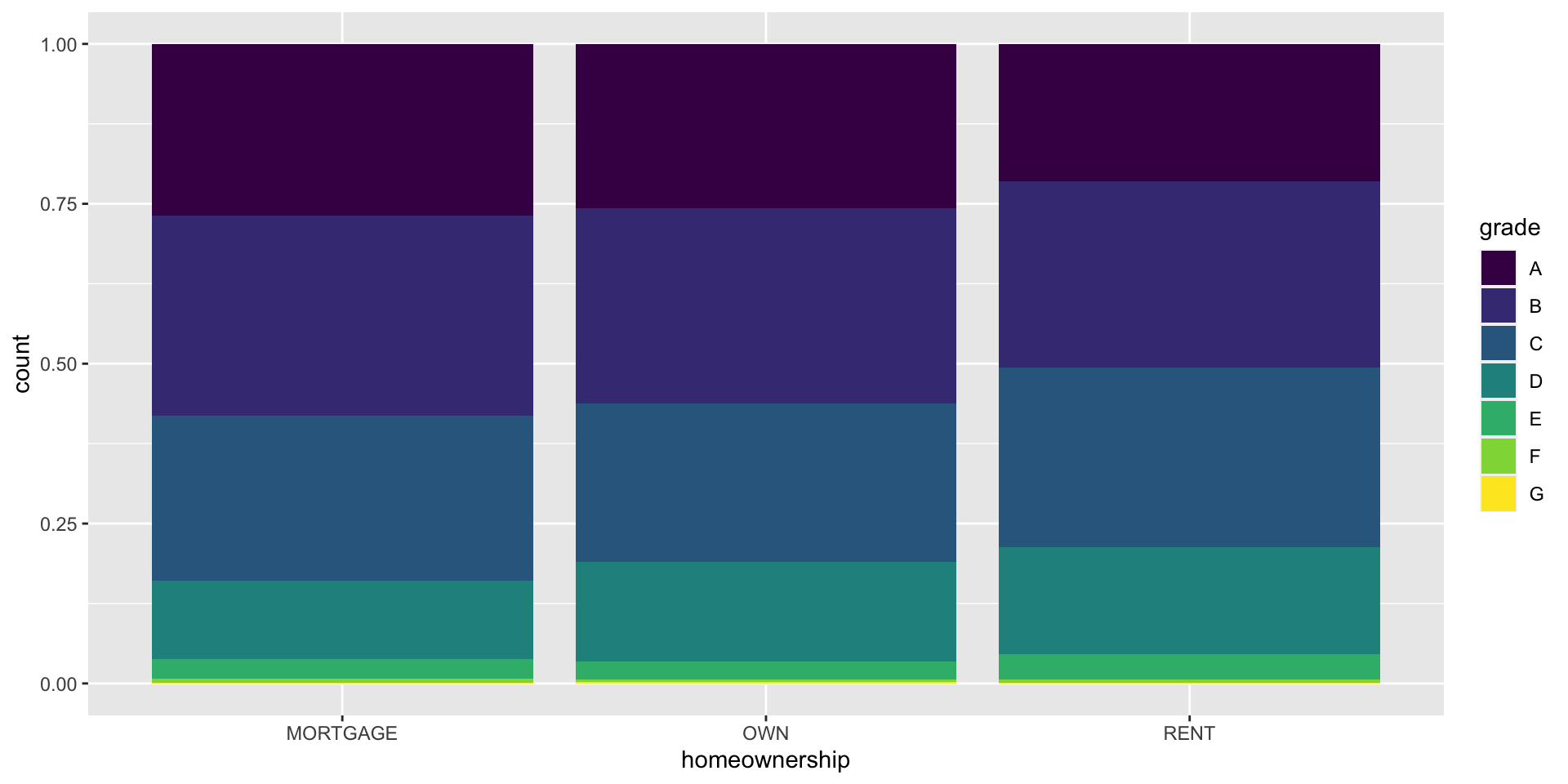
Segmented bar plot
Segmented bar plot
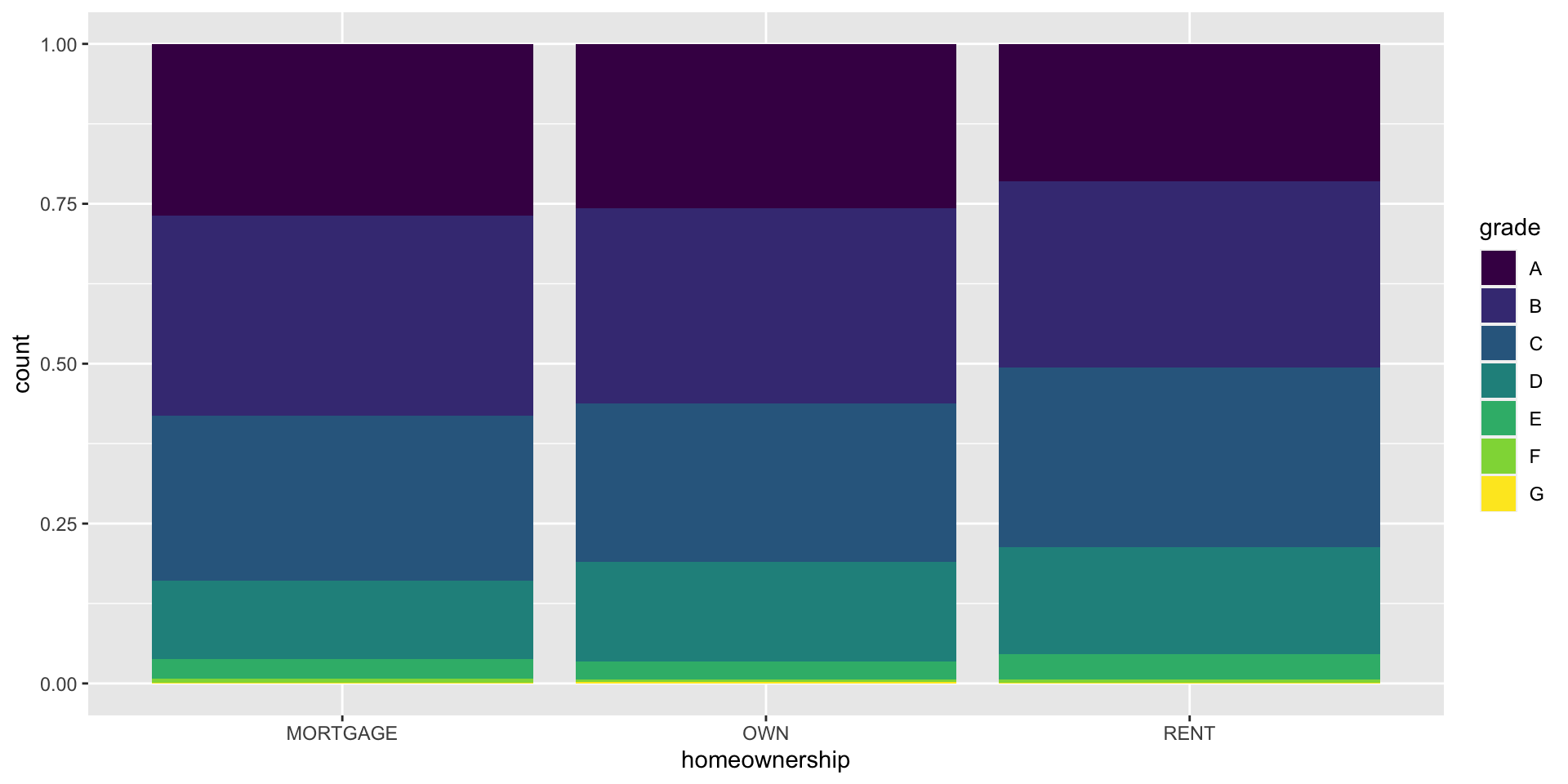
Which bar plot is a more useful representation for visualizing the relationship between homeownership and grade?
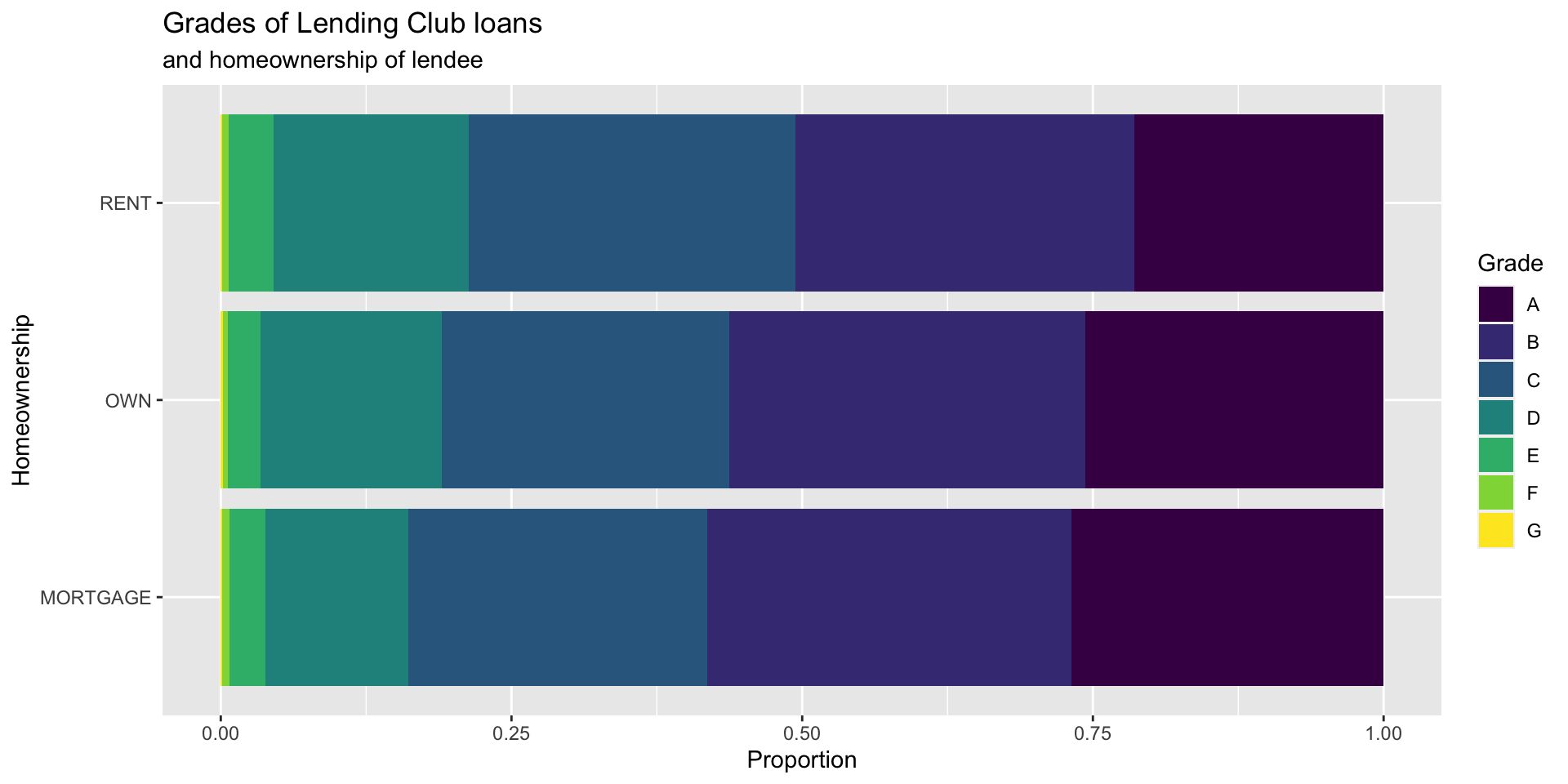
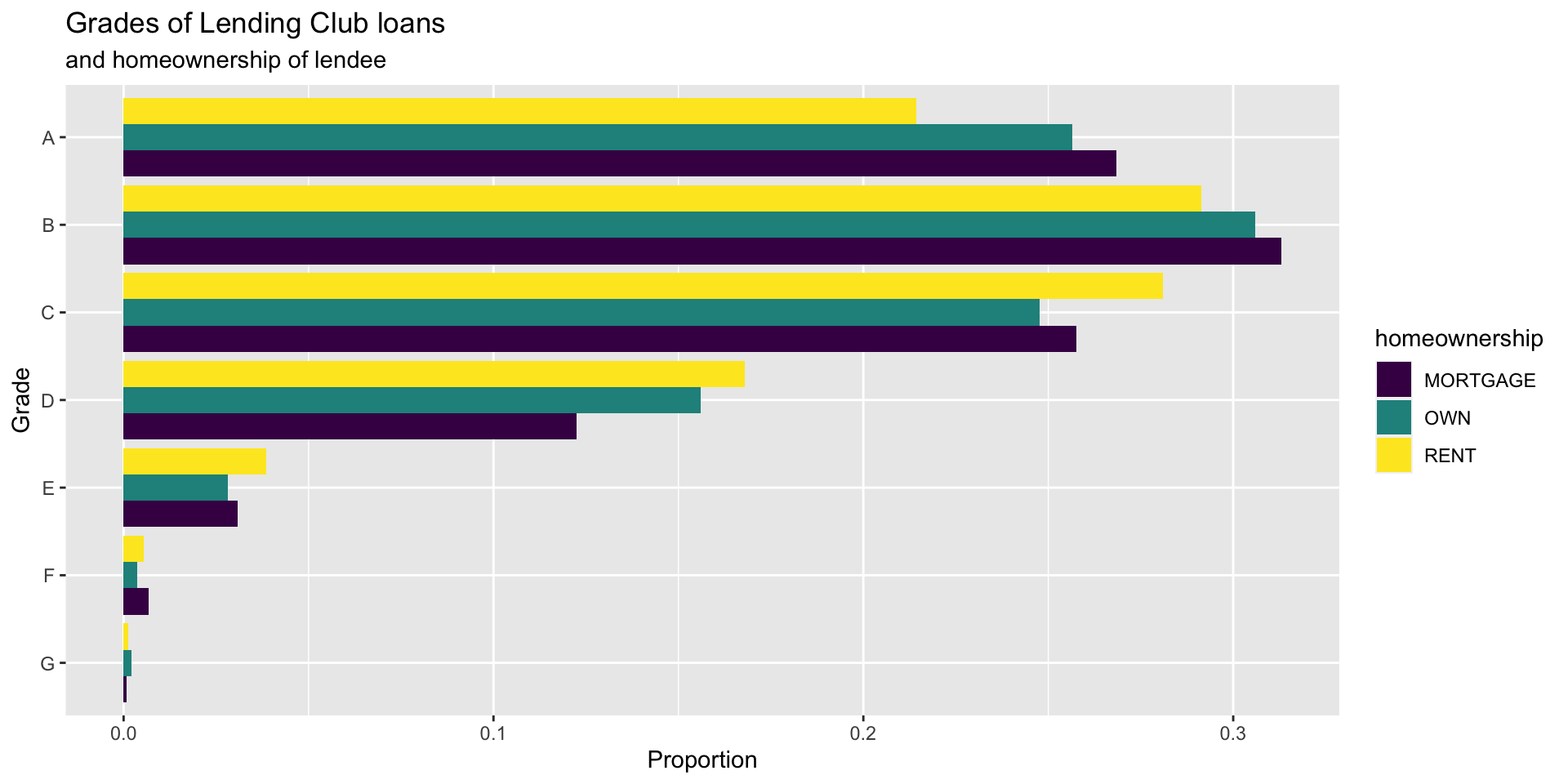
Customizing bar plots
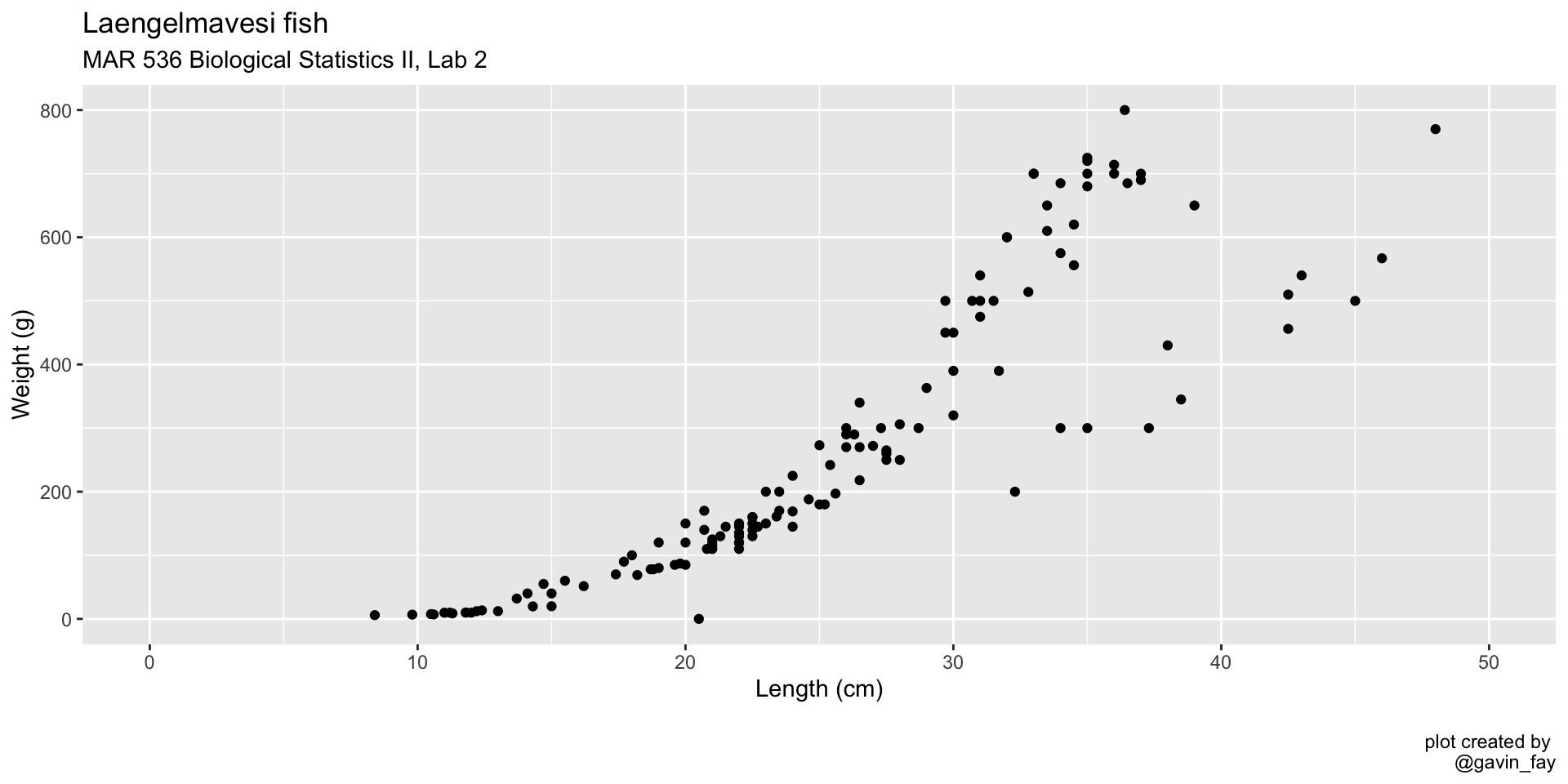
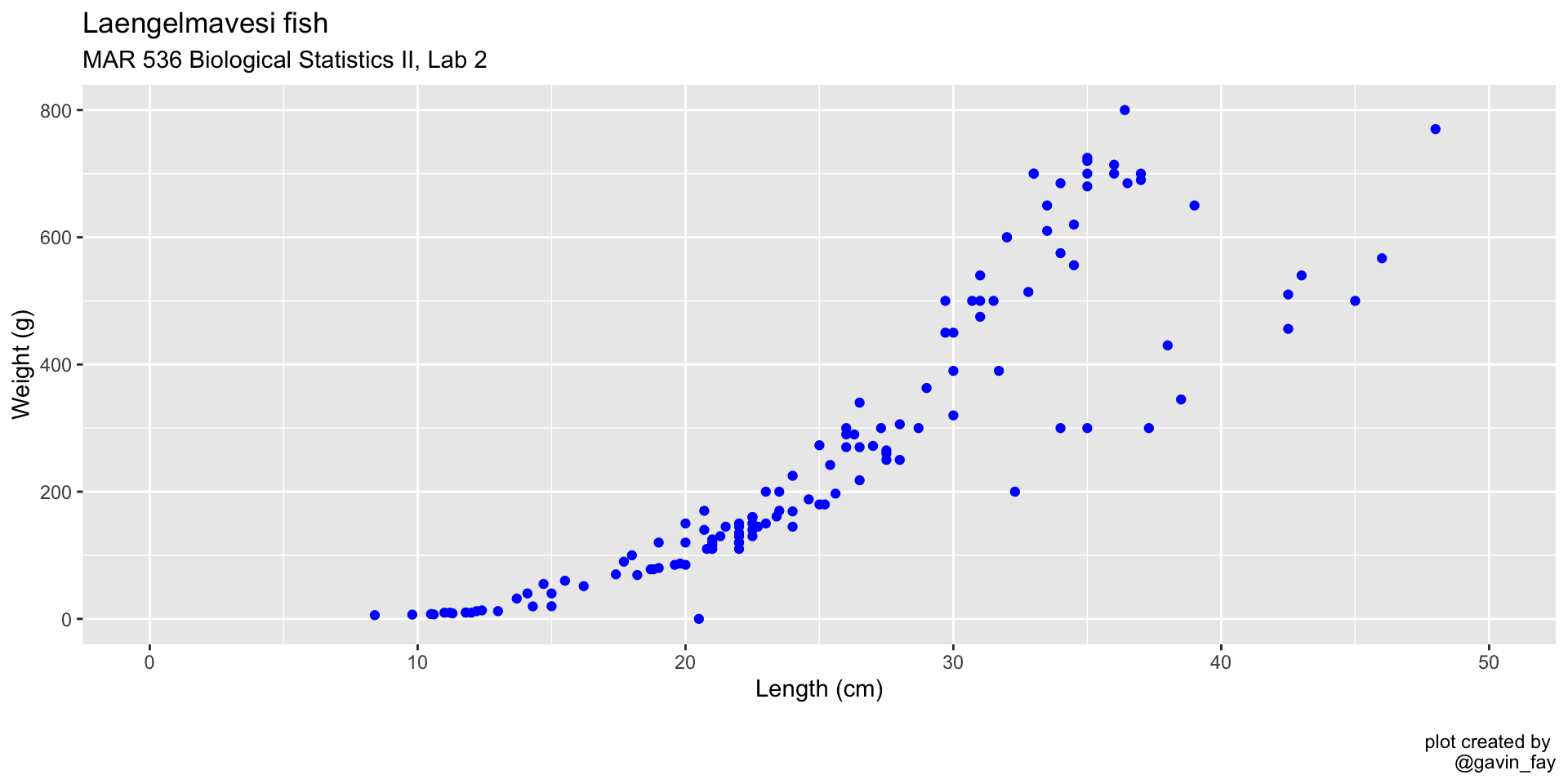
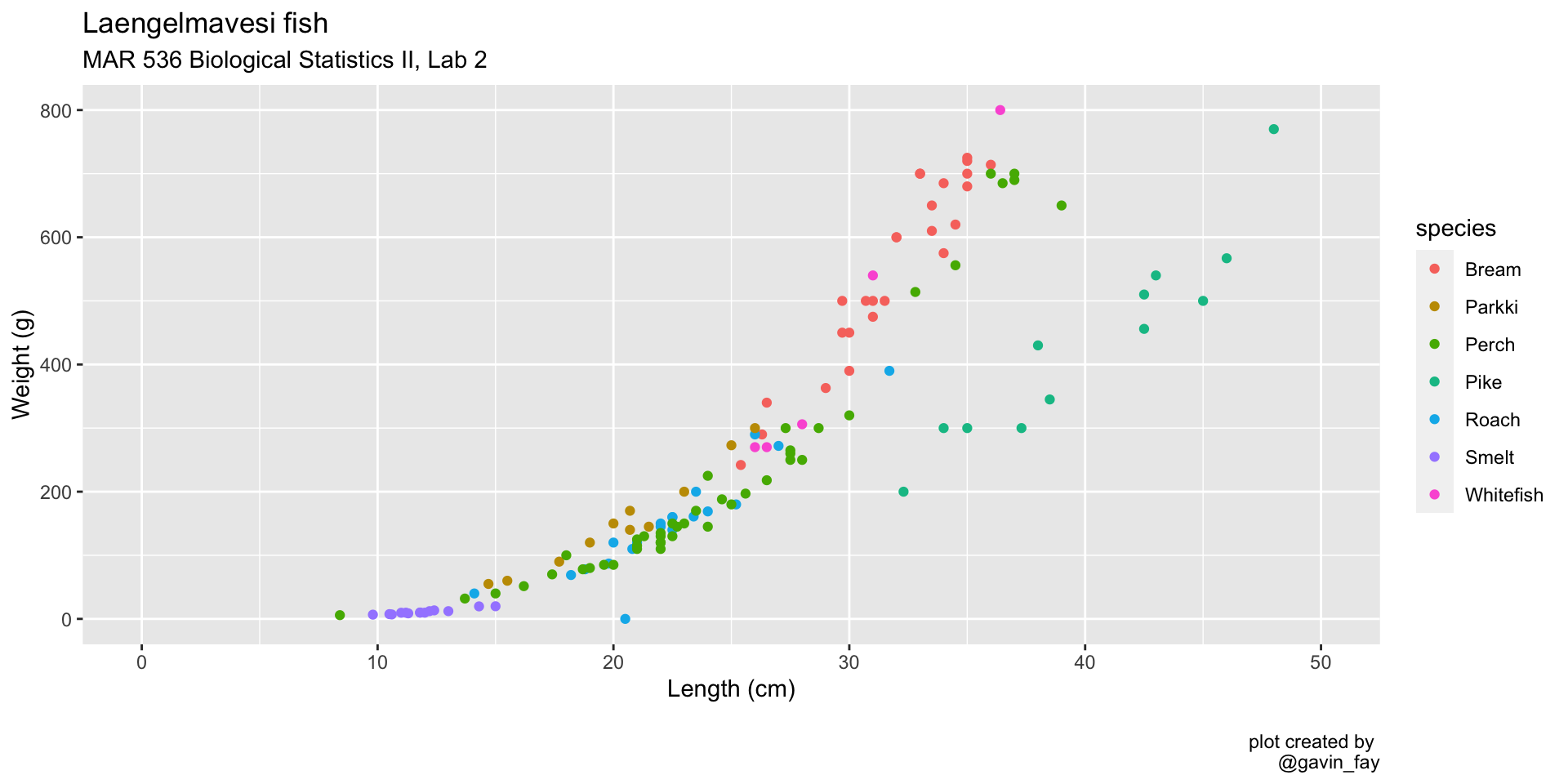
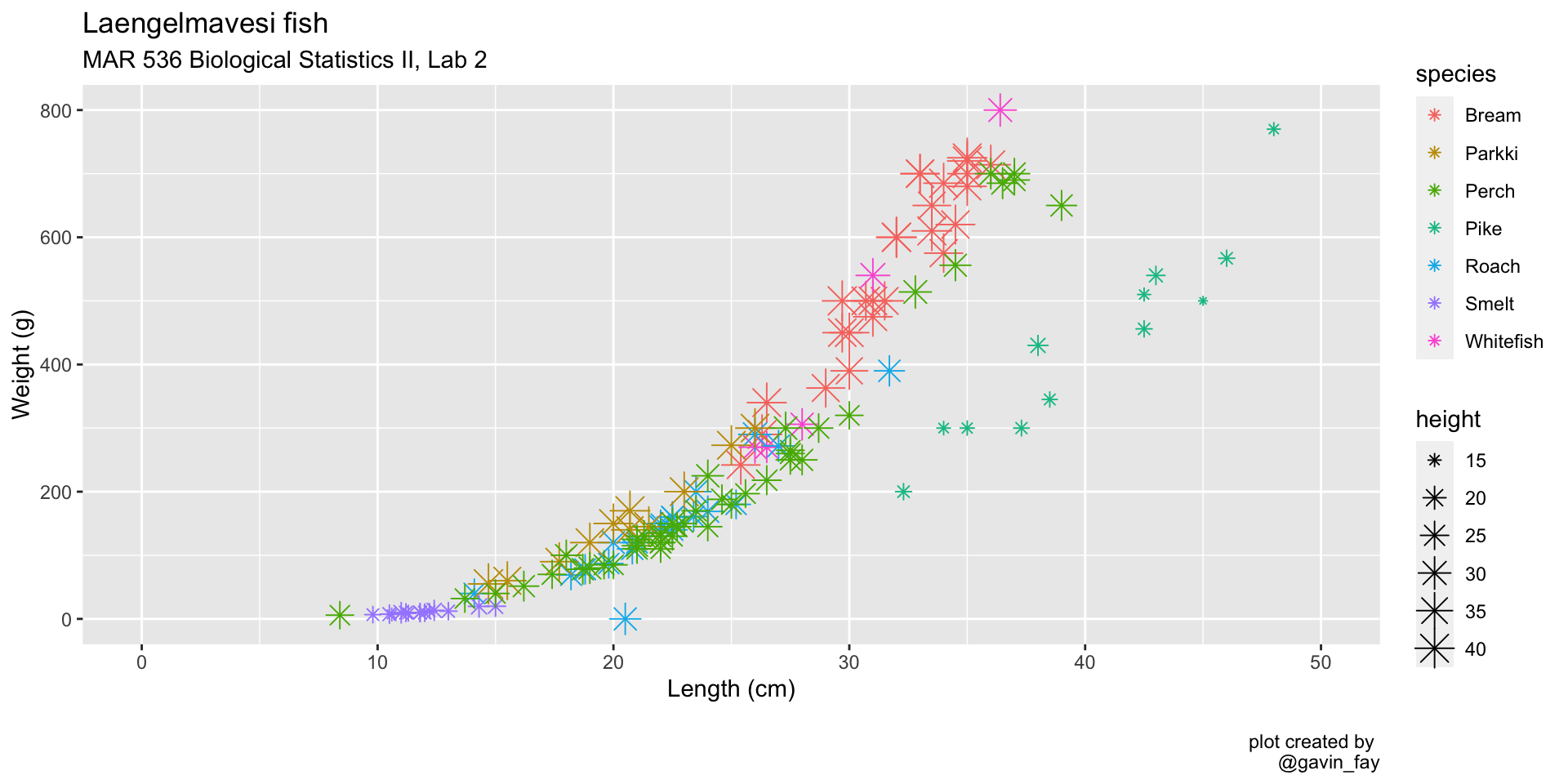
Lab exercise 3/3 (Laengelmavesi revisited)
Use the data in Laengelmavesi2.xlsx to create the following graphs. Make sure to add axis labels and plot titles.
- Create boxplots and histograms of the length distributions for each species.
- Plot all the weights vs the lengths. Include enough information that the data for each species can be identified.
- Plot the mean weight of each species as a function of the mean length, with the species names and mean heights also indicated on the plot.
- Create one plot of the heights as a function of the lengths. Add a line separating fish with height greater than 20cm.
- bonus Add to your plot from step (2) the mean weight and length for each species.